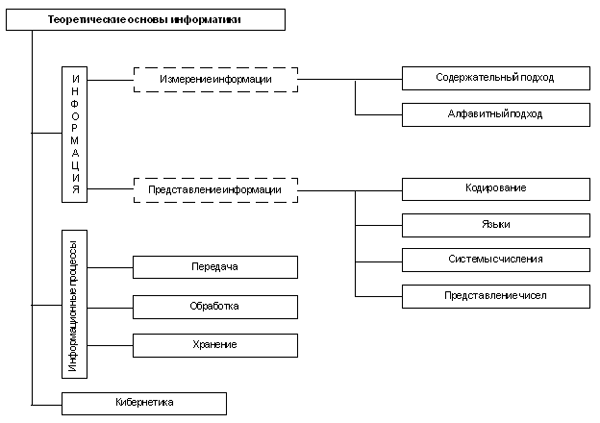
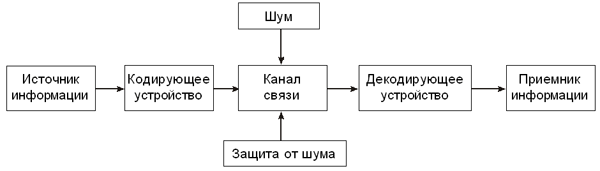
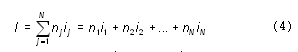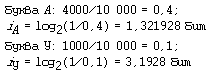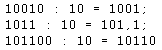ЭНЦИКЛОПЕДИЯ УЧИТЕЛЯ ИНФОРМАТИКИII. Теоретические основы информатикиСписок статей 1. Измерение информации — алфавитный подход 2. Измерение информации — содержательный подход 3. Информационные процессы 4. Информация 5. Кибернетика 6. Кодирование информации 7. Обработка информации 8. Передача информации 9. Представление чисел 10. Системы счисления 11. Хранение информации 12. Языки Основными объектами изучения науки информатики являются информация и информационные процессы. Информатика как самостоятельная наука возникла в середине ХХ столетия, однако научный интерес к информации и исследования в этой области появились раньше. В начале ХХ века активно развиваются
технические средства связи (телефон, телеграф,
радио). Важнейшая задача, поставленная теорией связи, — борьба с потерей информации в каналах передачи данных. В ходе решения этой задачи сформировалась теория кодирования, в рамках которой изобретались способы представления информации, позволяющие доносить содержание сообщения до адресата без искажения даже при наличии потерь передаваемого кода. Эти научные результаты имеют большое значение и сегодня, когда объемы информационных потоков в технических каналах связи выросли на многие порядки. Предшественником современной информатики явилась наука “Кибернетика”, основанная трудами Н.Винера в конце 1940-х — начале 50-х годов. В кибернетике произошло углубление понятия информации, было определено место информации в системах управления в живых организмах, в общественных и технических системах. Кибернетика исследовала принципы программного управления. Возникнув одновременно с появлением первых ЭВМ, кибернетика заложила научные основы как для их конструктивного развития, так и для многочисленных приложений. ЭВМ (компьютер) — автоматическое устройство, предназначенное для решения информационных задач путем осуществления информационных процессов: хранения, обработки и передачи информации. Описание основных принципов и закономерностей информационных процессов также относится к теоретическим основам информатики. Компьютер работает не с содержанием информации, которое способен воспринимать только человек, а с данными, представляющими информацию. Поэтому важнейшей задачей для компьютерных технологий является представление информации в форме данных, пригодных для их обработки. Данные и программы кодируются в двоичном виде. Обработка любого типа данных сводится в компьютере к вычислениям с двоичными числами. Именно поэтому компьютерные технологии еще называют цифровыми. Понятие о системах счисления, о представлении чисел в компьютере относятся к базовым понятиям информатики. Понятие “язык” происходит из лингвистики. Язык — это система символьного представления информации, используемая для ее хранения и передачи. Понятие языка относится к числу базовых понятий информатики, поскольку как данные, так и программы в компьютере представляются в виде символьных конструкций. Язык общения компьютера с человеком все более приближается к формам естественного языка. К фундаментальным основам информатики относится теория алгоритмов. Понятие алгоритма вводится в статье “Обработка информации”. Подробно эта тема раскрывается в пятом разделе энциклопедии.
1. Измерение информации. Алфавитный подходАлфавитный подход используется для измерения количества информации в тексте, представленном в виде последовательности символов некоторого алфавита. Такой подход не связан с содержанием текста. Количество информации в этом случае называется информационным объемом текста, который пропорционален размеру текста — количеству символов, составляющих текст. Иногда данный подход к измерению информации называют объемным подходом. Каждый символ текста несет определенное количество информации. Его называют информационным весом символа. Поэтому информационный объем текста равен сумме информационных весов всех символов, составляющих текст.
Здесь предполагается, что текст — это последовательная цепочка пронумерованных символов. В формуле (1) i1 обозначает информационный вес первого символа текста, i2 — информационный вес второго символа текста и т.д.; K — размер текста, т.е. полное число символов в тексте. Все множество различных символов, используемых для записи текстов, называется алфавитом. Размер алфавита — целое число, которое называется мощностью алфавита. Следует иметь в виду, что в алфавит входят не только буквы определенного языка, но все другие символы, которые могут использоваться в тексте: цифры, знаки препинания, различные скобки, пробел и пр. Определение информационных весов символов может происходить в двух приближениях: 1) в предположении равной вероятности (одинаковой частоты встречаемости) любого символа в тексте; 2) с учетом разной вероятности (разной частоты встречаемости) различных символов в тексте. Приближение равной вероятности символов в текстеЕсли допустить, что все символы
алфавита в любом тексте появляются с одинаковой
частотой, то информационный вес всех символов
будет одинаковым. Пусть N — мощность
алфавита. Тогда доля любого символа в тексте
составляет 1/N-ю часть текста. По определению
вероятности (см. “Измерение информации.
Содержательный подход” p = 1/N Согласно формуле К.Шеннона (см. “Измерение
информации. Содержательный подход” i = log2(1/p) = log2N (бит) (2) Следовательно, информационный вес
символа (i) и мощность алфавита (N) связаны
между собой по формуле Хартли (см. “Измерение
информации. Содержательный подход” 2i = N. Зная информационный вес одного символа (i) и размер текста, выраженный количеством символов (K), можно вычислить информационный объем текста по формуле: I = K · i (3) Эта формула есть частный вариант формулы (1), в случае, когда все символы имеют одинаковый информационный вес.
Из формулы (2) следует, что при N = 2 (двоичный алфавит) информационный вес одного символа равен 1 биту. С позиции алфавитного подхода к измерению информации 1 бит — это информационный вес символа из двоичного алфавита. Более крупной единицей измерения информации является байт. 1 байт — это информационный вес символа из алфавита мощностью 256. Поскольку 256 = 28, то из формулы Хартли следует связь между битом и байтом: 2i = 256 = 28 Отсюда: i = 8 бит = 1 байт Для представления текстов, хранимых и
обрабатываемых в компьютере, чаще всего
используется алфавит мощностью 256 символов.
Следовательно, Помимо бита и байта, для измерения информации применяются и более крупные единицы: 1 Кб (килобайт) = 210 байт = 1024 байта, 1 Мб (мегабайт) = 210 Кб = 1024 Кб, 1 Гб (гигабайт) = 210 Мб = 1024 Мб. Приближение разной вероятности встречаемости символов в текстеВ этом приближении учитывается, что в реальном тексте разные символы встречаются с разной частотой. Отсюда следует, что вероятности появления разных символов в определенной позиции текста различны и, следовательно, различаются их информационные веса. Статистический анализ русских текстов показывает, что частота появления буквы “о” составляет 0,09. Это значит, что на каждые 100 символов буква “о” в среднем встречается 9 раз. Это же число обозначает вероятность появления буквы “о” в определенной позиции текста: po = 0,09. Отсюда следует, что информационный вес буквы “о” в русском тексте равен:
Самой редкой в текстах буквой является буква “ф”. Ее частота равна 0,002. Отсюда:
Отсюда следует качественный вывод: информационный вес редких букв больше, чем вес часто встречающихся букв. Как же вычислить информационный объем текста с учетом разных информационных весов символов алфавита? Делается это по следующей формуле:
Здесь N — размер (мощность) алфавита; nj — число повторений символа номер j в тексте; ij — информационный вес символа номер j.
Алфавитный подход в курсе информатики основой школы В курсе информатики в основной школе знакомство учащихся с алфавитным подходом к измерению информации чаще всего происходит в контексте компьютерного представления информации. Основное утверждение звучит так: Количество информации измеряется размером двоичного кода, с помощью которого эта информация представлена Поскольку любые виды информации представляются в компьютерной памяти в форме двоичного кода, то это определение универсально. Оно справедливо для символьной, числовой, графической и звуковой информации.
Один знак (разряд) двоичного кода несет 1 бит информации. При объяснении способа измерения информационного объема текста в базовом курсе информатики данный вопрос раскрывается через следующую последовательность понятий: алфавит — размер двоичного кода символа — информационный объем текста. Логика рассуждений разворачивается от
частных примеров к получению общего правила.
Пусть в алфавите некоторого языка имеется всего 4
символа. Обозначим их: Следующий частный случай — 8-символьный алфавит, каждый символ которого можно закодировать 3-разрядным двоичным кодом, поскольку число размещений из двух знаков группами по 3 равно 23 = 8. Следовательно, информационный вес символа из 8-символьного алфавита равен 3 битам. И т.д. Обобщая частные примеры, получаем общее правило: с помощью b-разрядного двоичного кода можно закодировать алфавит, состоящий из N = 2b — символов. Пример 1. Для записи текста используются только строчные буквы русского алфавита и “пробел” для разделения слов. Какой информационный объем имеет текст, состоящий из 2000 символов (одна печатная страница)? Решение. В русском алфавите 33 буквы. Сократив его на две буквы (например, “ё” и “й”) и введя символ пробела, получаем очень удобное число символов — 32. Используя приближение равной вероятности символов, запишем формулу Хартли: 2i = 32 = 25 Отсюда: i = 5 бит — информационный вес каждого символа русского алфавита. Тогда информационный объем всего текста равен: I = 2000 · 5 = 10 000 бит Пример 2. Вычислить информационный объем текста размером в 2000 символов, в записи которого использован алфавит компьютерного представления текстов мощностью 256. Решение. В данном алфавите информационный вес каждого символа равен 1 байту (8 бит). Следовательно, информационный объем текста равен 2000 байт. В практических заданиях по данной теме важно отрабатывать навыки учеников в пересчете количества информации в разные единицы: биты — байты — килобайты — мегабайты — гигабайты. Если пересчитать информационный объем текста из примера 2 в килобайты, то получим: 2000 байт = 2000/1024 Пример 3. Объем сообщения, содержащего 2048 символов, составил 1/512 часть мегабайта. Каков размер алфавита, с помощью которого записано сообщение? Решение. Переведем информационный объем сообщения из мегабайтов в биты. Для этого данную величину умножим дважды на 1024 (получим байты) и один раз — на 8: I = 1/512 · 1024 · 1024 · 8 = 16 384 бита. Поскольку такой объем информации несут 1024 символа (К), то на один символ приходится: i = I/K = 16 384/1024 = 16 бит. Отсюда следует, что размер (мощность) использованного алфавита равен 216 = 65 536 символов. Объемный подход в курсе информатики в старших классах Изучая информатику в 10–11-х классах на базовом общеобразовательном уровне, можно оставить знания учащихся об объемном подходе к измерению информации на том же уровне, что описан выше, т.е. в контексте объема двоичного компьютерного кода. При изучении информатики на профильном уровне объемный подход следует рассматривать с более общих математических позиций, с использованием представлений о частотности символов в тексте, о вероятностях и связи вероятностей с информационными весами символов. Знание этих вопросов оказывается
важным для более глубокого понимания различия в
использовании равномерного и неравномерного
двоичного кодирования (см. “Кодирование
информации” Пример 4. В алфавите племени МУМУ всего 4 буквы (А, У, М, К), один знак препинания (точка) и для разделения слов используется пробел. Подсчитали, что в популярном романе “Мумука” содержится всего 10 000 знаков, из них: букв А — 4000, букв У — 1000, букв М — 2000, букв К — 1500, точек — 500, пробелов — 1000. Какой объем информации содержит книга? Решение. Поскольку объем книги достаточно большой, то можно допустить, что вычисленная по ней частота встречаемости в тексте каждого из символов алфавита характерна для любого текста на языке МУМУ. Подсчитаем частоту встречаемости каждого символа во всем тексте книги (т.е. вероятность) и информационные веса символов
Общий объем информации в книге вычислим как сумму произведений информационного веса каждого символа на число повторений этого символа в книге:
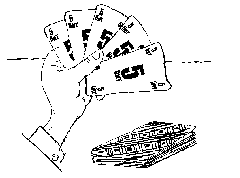
2. Измерение информации. Содержательный подходС позиции содержательного подхода к измерению информации решается вопрос о количестве информации в сообщении, получаемом человеком. Рассматривается следующая ситуация: 1) человек получает сообщение о некотором событии; при этом заранее известна неопределенность знания человека об ожидаемом событии. Неопределенность знания может быть выражена либо числом возможных вариантов события, либо вероятностью ожидаемых вариантов события; 2) в результате получения сообщения неопределенность знания снимается: из некоторого возможного количества вариантов оказался выбранным один; 3) по формуле вычисляется количество информации в полученном сообщении, выраженное в битах. Формула, используемая для вычисления количества информации, зависит от ситуаций, которых может быть две: 1. Все возможные варианты события равновероятны. Их число конечно и равно N. 2. Вероятности (p) возможных вариантов события разные и они заранее известны: {pi}, i = 1..N. Здесь по-прежнему N — число возможных вариантов события. Равновероятные события. Если обозначить буквой i количество информации в сообщении о том, что произошло одно из N равновероятных событий, то величины i и N связаны между собой формулой Хартли: 2i = N (1) Величина i измеряется в битах. Отсюда следует вывод: 1 бит — это количество информации в сообщении об одном из двух равновероятных событий. Формула Хартли — это показательное уравнение. Если i — неизвестная величина, то решением уравнения (1) будет: i = log2N (2) Формулы (1) и (2) тождественны друг другу. Иногда в литературе формулой Хартли называют (2). Пример 1. Сколько информации содержит сообщение о том, что из колоды карт достали даму пик? В колоде 32 карты. В перемешанной колоде выпадение любой карты — равновероятные события. Если i — количество информации в сообщении о том, что выпала конкретная карта (например, дама пик), то из уравнения Хартли: 2i = 32 = 25 Отсюда: i = 5 бит.
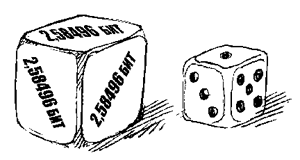
Пример 2. Сколько информации содержит сообщение о выпадении грани с числом 3 на шестигранном игральном кубике? Считая выпадение любой грани событием равновероятным, запишем формулу Хартли: 2i = 6. Отсюда: i = log26 = 2,58496 бит.
Неравновероятные события (вероятностный подход)Если вероятность некоторого события равна p, а i (бит) — это количество информации в сообщении о том, что произошло это событие, то данные величины связаны между собой формулой: 2i = 1/p (3) Решая показательное уравнение (3) относительно i, получаем: i = log2(1/p) (4) Формула (4) была предложена К.Шенноном, поэтому ее называют формулой Шеннона.
Обсуждение связи между количеством информации в сообщении и его содержанием может происходить на разных уровнях глубины. Качественный подход Качественный подход, который может использоваться на уровне пропедевтики базового курса информатики (5–7-е классы) или в базовом курсе (8–9-е классы). На данном уровне изучения обсуждается следующая цепочка понятий: информация — сообщение — информативность сообщения. Исходная посылка: информация — это знания людей, получаемые ими из различных сообщений. Следующий вопрос: что такое сообщение? Сообщение — это информационный поток (поток данных), который в процессе передачи информации поступает к принимающему его субъекту. Сообщение — это и речь, которую мы слушаем (радиосообщение, объяснение учителя), и воспринимаемые нами зрительные образы (фильм по телевизору, сигнал светофора), и текст книги, которую мы читаем, и т.д. Вопрос об информативности сообщения следует обсуждать на примерах, предлагаемых учителем и учениками. Правило: информативным назовем сообщение, которое пополняет знания человека, т.е. несет для него информацию. Для разных людей одно и то же сообщение с точки зрения его информативности может быть разным. Если сведения “старые”, т.е. человек это уже знает, или содержание сообщения непонятно человеку, то для него это сообщение неинформативно. Информативно то сообщение, которое содержит новые и понятные сведения. Примеры неинформативных сообщений для ученика 8-го класса: 1)“Столица Франции — Париж” (не новое); 2) “Коллоидная химия изучает дисперсионные состояния систем, обладающих высокой степенью раздробленности” (не понятное). Пример информативного сообщения (для тех, кто этого не знал): “Эйфелева башня имеет высоту 300 метров и вес 9000 тонн”. Введение понятия “информативность сообщения” является первым подходом к изучению вопроса об измерении информации в рамках содержательной концепции. Если сообщение неинформативно для человека, то количество информации в нем, с точки зрения этого человека, равно нулю. Количество информации в информативном сообщении больше нуля. Количественный подход в приближении равновероятности Данный подход может изучаться либо в углубленном варианте базового курса в основной школе, либо при изучении информатики в 10–11-х классах на базовом уровне. Рассматривается следующая цепочка понятий: равновероятные события — неопределенность знаний — бит как единица измерения информации — формула Хартли — решение показательного уравнения для N равного целым степеням двойки. Раскрывая понятие равновероятности, следует отталкиваться от интуитивного представления детей, подкрепив его примерами. События равновероятны, если ни одно из них не имеет преимущества перед другими. Введя частное определение бита, которое было дано выше, затем его следует обобщить: Сообщение, уменьшающее неопределенность знаний в 2 раза, несет 1 бит информации. Это определение подкрепляется примерами сообщений об одном событии из четырех (2 бита), из восьми (3 бита) и т.д. На данном уровне можно не обсуждать варианты значений N, не равные целым степеням двойки, чтобы не сталкиваться с проблемой вычисления логарифмов, которые в курсе математики пока не изучались. Если же у детей будут возникать вопросы, например: “Сколько информации несет сообщение о результате бросания шестигранного кубика”, — то объяснение можно построить следующим образом. Из уравнения Хартли: 2i = 6. Поскольку 22 < 6 < 23, следовательно, 2 < i < 3. Затем сообщить более точное значение (с точностью до пяти знаков после запятой), что i = 2,58496 бит. Отметить, что при данном подходе количество информации может быть выражено дробной величиной. Вероятностный подход к измерению информации Он может изучаться в 10–11-х классах в рамках общеобразовательного курса профильного уровня или в элективном курсе, посвященном математическим основам информатики. Здесь должно быть введено математически корректное определение вероятности. Кроме того, ученики должны знать функцию логарифма и ее свойства, уметь решать показательные уравнения. Вводя понятие вероятности, следует сообщить, что вероятность некоторого события — это величина, которая может принимать значения от нуля до единицы. Вероятность невозможного события равна нулю (например: “завтра Солнце не взойдет над горизонтом”), вероятность достоверного события равна единице (например: “Завтра солнце взойдет над горизонтом”). Следующее положение: вероятность некоторого события определяется путем многократных наблюдений (измерений, испытаний). Такие измерения называют статистическими. И чем большее количество измерений выполнено, тем точнее определяется вероятность события. Математическое определение вероятности звучит так: вероятность равна отношению числа исходов, благоприятствующих данному событию, к общему числу равновозможных исходов. Пример 3. На автобусной остановке останавливаются два маршрута автобусов: № 5 и № 7. Ученику дано задание: определить, сколько информации содержит сообщение о том, что к остановке подошел автобус № 5, и сколько информации в сообщении о том, что подошел автобус № 7. Ученик провел исследование. В течение всего рабочего дня он подсчитал, что к остановке автобусы подходили 100 раз. Из них — 25 раз подходил автобус № 5 и 75 раз подходил автобус № 7. Сделав предположение, что с такой же частотой автобусы ходят и в другие дни, ученик вычислил вероятность появления на остановке автобуса № 5: p5 = 25/100 = 1/4, и вероятность появления автобуса № 7: p7 = 75/100 = 3/4. Отсюда, количество информации в сообщении об автобусе № 5 равно: i5 = log24 = 2 бита. Количество информации в сообщении об автобусе № 7 равно: i7 = log2(4/3) = log24 – log23 = 2 – 1,58496 = 0,41504 бита.
Обратите внимание на следующий качественный вывод: чем вероятность события меньше, тем больше количество информации в сообщении о нем. Количество информации о достоверном событии равно нулю. Например, сообщение “Завтра наступит утро” является достоверным и его вероятность равна единице. Из формулы (3) следует: 2i = 1/1 = 1. Отсюда, i = 0 бит. Формула Хартли (1) является частным случаем формулы (3). Если имеется N равновероятных событий (результат бросания монеты, игрального кубика и т.п.), то вероятность каждого возможного варианта равна p = 1/N. Подставив в (3), снова получим формулу Хартли: 2i = N. Если бы в примере 3 автобусы № 5 и № 7 приходили бы к остановке из 100 раз каждый по 50, то вероятность появления каждого из них была бы равна 1/2. Следовательно, количество информации в сообщении о приходе каждого автобуса равно i = log22 = 1 биту. Пришли к известному варианту информативности сообщения об одном из двух равновероятных событий. Пример 4. Рассмотрим другой вариант задачи об автобусах. На остановке останавливаются автобусы № 5 и № 7. Сообщение о том, что к остановке подошел автобус № 5, несет 4 бита информации. Вероятность появления на остановке автобуса с № 7 в два раза меньше, чем вероятность появления автобуса № 5. Сколько бит информации несет сообщение о появлении на остановке автобуса № 7? Запишем условие задачи в следующем виде: i5 = 4 бита, p5 = 2 · p7 Вспомним связь между вероятностью и количеством информации: 2i = 1/p Отсюда: p = 2–i Подставляя в равенство из условия задачи, получим:
Отсюда:
Из полученного результата следует вывод: уменьшение вероятности события в 2 раза увеличивает информативность сообщения о нем на 1 бит. Очевидно и обратное правило: увеличение вероятности события в 2 раза уменьшает информативность сообщения о нем на 1 бит. Зная эти правила, предыдущую задачу можно было решить “в уме”. 3. Информационные процессыПредметом изучения науки информатики является информация и информационные процессы. Как нет единственного общепринятого определения информации (см. “Информация” ), так же нет единства и в трактовке понятия “информационные процессы”. Подойдем к осмыслению этого понятия с терминологической позиции. Слово процесс обозначает некоторое событие, происходящее во времени: судебный процесс, производственный процесс, учебный процесс, процесс роста живого организма, процесс нефтеперегонки, процесс горения топлива, процесс полета космического корабля и т.д. Всякий процесс связан с какими-то действиями, выполняемыми человеком, силами природы, техническими устройствами, а также вследствие их взаимодействия. У всякого процесса есть объект воздействия: подсудимый, ученики, нефть, горючее, космический корабль. Если процесс связан с целенаправленной деятельностью человека, то такого человека можно назвать исполнителем процесса: судья, учитель, космонавт. Если процесс осуществляется с помощью автоматического устройства, то оно является исполнителем процесса: химический реактор, автоматическая космическая станция. Очевидно, что в информационных процессах объектом воздействия является информация. В учебном пособии С.А. Бешенкова, Е.А. Ракитиной дается такое определение: “В наиболее общем виде информационный процесс определяется как совокупность последовательных действий (операций), производимых над информацией (в виде данных, сведений, фактов, идей, гипотез, теорий и пр.) для получения какого-либо результата (достижения цели)”[2]. Дальнейший анализ понятия “информационные процессы” зависит от подхода к понятию информации, от ответа на вопрос: “Что такое информация?”. Если принять атрибутивную точку зрения на информацию (см. “Информация” ), то следует признать, что информационные процессы происходят как в живой, так и в неживой природе. Например, в результате физического взаимодействия между Землей и Солнцем, между электронами и ядром атома, между океаном и атмосферой. С позиции функциональной концепции информационные процессы происходят в живых организмах (растениях, животных) и при их взаимодействии. С антропоцентрической точки зрения исполнителем информационных процессов является человек. Информационные процессы являются функцией человеческого сознания (мышления, интеллекта). Человек может осуществлять их самостоятельно, а также с помощью созданных им орудий информационной деятельности. Любая, сколь угодно сложная информационная деятельность человека сводится к трем основным видам действий с информацией: сохранению, приему/передаче, обработке. Обычно вместо “прием-передача” говорят просто “передача”, понимая этот процесс как двусторонний: передача от источника к приемнику (синоним — “транспортировка”). Хранение, передача и обработка информации — основные виды информационных процессов. Выполнение названных действий с информацией связано с ее представлением в виде данных. Всевозможные орудия информационной деятельности человека (например: бумага и ручка, технические каналы связи, вычислительные устройства и пр.) используются для хранения, обработки и передачи данных. Если проанализировать деятельность какой-нибудь организации (отдела кадров предприятия, бухгалтерии, научной лаборатории), работающей с информацией “по старинке”, без применения компьютеров, то для обеспечения ее деятельности требуются три вида средств: — бумага и пишущие средства (ручки, пишущие машинки, чертежные инструменты) для фиксации информации с целью хранения; — средства связи (курьеры, телефоны, почта) для приема и передачи информации; — вычислительные средства (счеты, калькуляторы) для обработки информации. В наше время все эти виды информационной деятельности выполняются с помощью компьютерной техники: данные хранятся на цифровых носителях, передача происходит с помощью электронной почты и других услуг компьютерных сетей, вычисления и другие виды обработки выполняются на компьютере. Состав основных устройств компьютера определяется именно тем, что компьютер предназначен для осуществления хранения, обработки и передачи данных. Для этого в него входят память, процессор, внутренние каналы и внешние устройства ввода-вывода (см. “Компьютер” ). Для того чтобы терминологически разделить процессы работы с информацией, происходящие в человеческом сознании, и процессы работы с данными, происходящими в компьютерных системах, А.Я. Фридланд [7] предлагает их называть по-разному: первые — информационными процессами, вторые — информатическими процессами. Другой подход к трактовке информационных процессов предлагает кибернетика. Информационные процессы происходят в различных системах управления, имеющих место в живой природе, в человеческом организме, в социальных системах, в технических системах (в т.ч. в компьютере). Например, кибернетический подход применяется в нейрофизиологии (см. “Информация” ), где управление физиологическими процессами в организме животного и человека, происходящее на бессознательном уровне, рассматривается как информационный процесс. В нейронах (клетках мозга) хранится и обрабатывается информация, по нервным волокнам происходит передача информации в виде сигналов электрохимической природы. Генетика установила, что наследственная информация хранится в молекулах ДНК, входящих в состав ядер живых клеток. Она определяет программу развития организма (т.е. управляет этим процессом), которая реализуется на бессознательном уровне. Таким образом, и в кибернетической трактовке информационные процессы сводятся к хранению, передаче и обработке информации, представленной в виде сигналов, кодов различной природы.
На любом этапе изучения информатики в школе представления об информационных процессах несут в себе систематизирующую методическую функцию. Изучая устройство компьютера, ученики должны получить четкое понимание того, с помощью каких устройств происходит хранение, обработка и передача данных. При изучении программирования следует обратить внимание учеников на то, что программа работает с данными, хранимыми в памяти компьютера (как и сама программа), что команды программы определяют действия процессора по обработке данных и действие устройств ввода-вывода по приему-передаче данных. Осваивая информационные технологии, следует обращать внимание на то, что эти технологии также ориентированы на выполнение хранения, обработки и передачи информации. Подробнее см. статьи “Хранение информации”, “Обработка информации”, “Передача информации” 2. 4. ИнформацияПроисхождение термина “информация”Слово “информация” происходит от латинского information, которое переводится как разъяснение, изложение. В толковом словаре В.И. Даля нет слова “информация”. Термин “информация” вошел в употребление в русскую речь с середины ХХ века. В наибольшей степени понятие информации обязано своим распространением двум научным направлениям: теории связи и кибернетике. Результатом развития теории связи стала теория информации, основателем которой является Клод Шеннон. Однако К.Шеннон не давал определения информации, в то же время, определяя количество информации. Теория информации посвящена решению проблемы измерения информации. В науке кибернетике, основанной Норбертом Винером, понятие информации является центральным (см. “Кибернетика” 2). Принято считать, что именно Н.Винер ввел понятие информации в научное употребление. Тем не менее в своей первой книге, посвященной кибернетике, Н.Винер не дает определения информации. “Информация есть информация, а не материя и не энергия”[3], — писал Винер. Тем самым понятие информации, с одной стороны, противопоставляется понятиям материи и энергии, с другой — ставится в один ряд с этими понятиями по степени их общности и фундаментальности. Отсюда по крайней мере понятно, что информация — это то, что не может быть отнесено ни к материи, ни к энергии. Информация в философииОсмыслением информации как фундаментального понятия занимается наука философия. Согласно одной из философских концепций, информация является свойством всего сущего, всех материальных объектов мира. Такая концепция информации называется атрибутивной (информация — атрибут всех материальных объектов). Информация в мире возникла вместе со Вселенной. В этом смысле информация — это мера упорядоченности, структурированности любой материальной системы. Процессы развития мира от первоначального хаоса, наступившего после “Большого взрыва”, до образования неорганических систем, затем органических (живых) систем связаны с нарастанием информационного содержания. Это содержание объективно, не зависимо от человеческого сознания. В куске угля содержится информация о событиях, происходивших в далекие времена. Однако извлечь эту информацию способен лишь пытливый ум человека. Другую философскую концепцию информации называют функциональной. Согласно функциональному подходу, информация появилась с возникновением жизни, так как связана с функционированием сложных самоорганизующихся систем, к которым относятся живые организмы и человеческое общество. Можно еще сказать так: информация — это атрибут, свойственный только живой природе. Это один из существенных признаков, отделяющих в природе живое от неживого. Третья философская концепция информации — антропоцентрическая, согласно которой информация существует лишь в человеческом сознании, в человеческом восприятии. Информационная деятельность присуща только человеку, происходит в социальных системах. Создавая информационную технику, человек создает инструменты для своей информационной деятельности. Можно сказать, что употребление понятия “информация” в повседневной жизни происходит в антропоцентрическом контексте. Для любого из нас естественно воспринимать информацию как сообщения, которыми обмениваются люди. Например, СМИ — средства массовой информации предназначены для распространения сообщений, новостей среди населения. Информация в биологииВ ХХ веке понятие информации повсеместно проникает в науку. Информационные процессы в живой природе исследует биология. Нейрофизиология (раздел биологии) изучает механизмы нервной деятельности животного и человека. Эта наука строит модель информационных процессов, происходящих в организме. Поступающая извне информация превращается в сигналы электрохимической природы, которые от органов чувств передаются по нервным волокнам к нейронам (нервным клеткам) мозга. Мозг передает управляющую информацию в виде сигналов той же природы к мышечным тканям, управляя, таким образом, органами движения. Описанный механизм хорошо согласуется с кибернетической моделью Н.Винера (см. “Кибернетика” 2). В другой биологической науке — генетике используется понятие наследственной информации, заложенной в структуре молекул ДНК, присутствующих в ядрах клеток живых организмов (растений, животных). Генетика доказала, что эта структура является своеобразным кодом, определяющим функционирование всего организма: его рост, развитие, патологии и пр. Через молекулы ДНК происходит передача наследственной информации от поколения к поколению. Методические рекомендацииИзучая информатику в основной школе (базовый курс), не следует углубляться в сложности проблемы определения информации. Понятие информации дается в содержательном контексте: Информация — это смысл, содержание сообщений, получаемых человеком из внешнего мира посредством его органов чувств. Понятие информации раскрывается через цепочку: сообщение — смысл — информация – знания Сообщения человек воспринимает с помощью своих органов чувств (по большей части через зрение и слух). Если человеку понятен смысл, заключенный в сообщении, то можно сказать, что это сообщение несет человеку информацию. Например, сообщение на незнакомом языке не содержит информации для данного человека, а сообщение на родном языке понятно, поэтому информативно. Воспринятая и сохраненная в памяти информация пополняет знания человека. Наши знания — это систематизированная (связанная) информация в нашей памяти. При раскрытии понятия информации с точки зрения содержательного подхода следует отталкиваться от интуитивных представлений об информации, имеющихся у детей. Целесообразно вести беседу в форме диалога, задавая ученикам вопросы, на которые они в состоянии ответить. Вопросы, например, можно задавать в следующем порядке. — Расскажите, откуда вы получаете информацию? Наверняка услышите в ответ: — Из книг, радио и телепередач. Дальше попросите учеников привести примеры какой-нибудь информации, которую они получили сегодня. Например, кто-нибудь ответит: — Утром по радио я слышал прогноз погоды. Ухватившись за такой ответ, учитель подводит учеников к окончательному выводу: — Значит, вначале ты не знал, какая будет погода, а после прослушивания радио стал знать. Следовательно, получив информацию, ты получил новые знания! Таким образом, учитель вместе с учениками приходит к определению: информация для человека — это сведения, пополняющие знания человека, которые он получает из различных источников. Далее на многочисленных знакомых детям примерах следует закрепить это определение. Установив связь между информацией и знаниями людей, неизбежно приходишь к выводу, что информация — это содержимое нашей памяти, ибо человеческая память и есть средство хранения знаний. Разумно назвать такую информацию внутренней, оперативной информацией, которой обладает человек. Однако люди хранят информацию не только в собственной памяти, но и в записях на бумаге, на магнитных носителях и пр. Такую информацию можно назвать внешней (по отношению к человеку). Чтобы человек мог ей воспользоваться (например, приготовить блюдо по кулинарному рецепту), он должен сначала ее прочитать, т.е. обратить во внутреннюю форму, а затем уже производить какие-то действия. Вопрос о классификации знаний (а стало быть, информации) очень сложный. В науке существуют различные подходы к нему. Особенно много занимаются этим вопросом специалисты в области искусственного интеллекта. В рамках базового курса достаточно ограничиться делением знаний на декларативные и процедурные. Описание декларативных знаний можно начинать со слов: “Я знаю, что…”. Описание процедурных знаний — со слов: “Я знаю, как…”. Нетрудно дать примеры на оба типа знаний и предложить детям придумать свои примеры. Учитель должен хорошо понимать пропедевтическое значение обсуждения данных вопросов для будущего знакомства учеников с устройством и работой компьютера. У компьютера, подобно человеку, есть внутренняя — оперативная — память и внешняя — долговременная — память. Деление знаний на декларативные и процедурные в дальнейшем можно увязать с делением компьютерной информации на данные — декларативная информация и программы — процедурная информация. Использование дидактического приема аналогии между информационной функцией человека и компьютером позволит ученикам лучше понять суть устройства и работы ЭВМ. Исходя из позиции “знания человека — это сохраненная информация”, учитель сообщает ученикам, что и запахи, и вкусы, и тактильные (осязательные) ощущения тоже несут информацию человеку. Обоснование этому очень простое: раз мы помним знакомые запахи и вкусы, узнаем на ощупь знакомые предметы, значит, эти ощущения хранятся в нашей памяти, а стало быть, являются информацией. Отсюда вывод: с помощью всех своих органов чувств человек получает информацию из внешнего мира. Как с содержательной, так и с методической точки зрения очень важно различать смысл понятий “информация” и “данные”. К представлению информации в любой знаковой системе (в том числе используемой в компьютерах) следует применять термин “данные”. А информация — это смысл, заключенный в данных, заложенный в них человеком и понятный только человеку. Компьютер работает с данными: получает входные данные, осуществляет их обработку, передает человеку выходные данные — результаты. Смысловую же интерпретацию данных осуществляет человек. Тем не менее в разговорной речи, в литературе часто говорят и пишут о том, что компьютер хранит, обрабатывает, передает и принимает информацию. Это справедливо, если компьютер не отрывать от человека, рассматривая его как инструмент, с помощью которого человек осуществляет информационные процессы. 5. КибернетикаСлово “кибернетика” — греческого происхождения, буквально обозначающее искусство управления. В IV веке до н.э. в трудах Платона этот термин употреблялся для обозначения управления в общем смысле. В XIX веке А.Ампер предложил назвать кибернетикой науку об управлении человеческим обществом. В современном толковании кибернетика — наука, изучающая общие законы управления и взаимосвязи в организованных системах (машинах, живых организмах, в обществе). Возникновение кибернетики как самостоятельной науки связывается с выходом книг американского ученого Норберта Винера “Кибернетика, или Управление и связь в животном и машине” в 1948 г. и “Кибернетика и общество” в 1954 г. Основным научным открытием кибернетики стало обоснование единства законов управления в естественных и искусственных системах. К такому выводу Н.Винер пришел, построив информационную модель процессов управления.
Норберт Винер (1894–1964), США Подобная схема была известна в теории автоматического регулирования. Винер обобщил ее на все виды систем, абстрагируясь от конкретных механизмов связи, рассматривая эту связь как информационную.
Схема управления с обратной связью По каналу прямой связи передается управляющая информация — команды управления. По каналу обратной связи передается информация о состоянии управляемого объекта, о его реакции на управляющее воздействие, а также о состоянии внешней среды, что часто является существенным фактором в управлении. Кибернетика развивает понятие информации как содержание сигналов, передаваемых по каналам связи. Кибернетика развивает понятие алгоритма как управляющей информации, которой должен владеть управляющий объект для выполнения своей работы. Появление кибернетики происходит одновременно с созданием электронно-вычислительных машин. Связь ЭВМ и кибернетики настолько тесная, что эти понятия в 1950-е годы нередко отождествляли. ЭВМ называли кибернетическими машинами. Связь ЭВМ и кибернетики существует в двух аспектах. Во-первых, ЭВМ — это самоуправляемый автомат, в котором роль управляющего играет устройство управления, имеющееся в составе процессора, а все остальные устройства являются объектами управления. Прямая и обратная связь осуществляется по информационным каналам, а алгоритм представляется в виде программы на машинном языке (языке, “понятном” процессору), хранящейся в памяти ЭВМ. Во-вторых, с изобретением ЭВМ открывалась перспектива использования машины в качестве управляющего объекта в самых различных системах. Возникает возможность создания сложных систем с программным управлением, передачи автоматическим устройствам многих видов человеческой деятельности. Развитие линии “кибернетика — ЭВМ” привело в 1960-х годах к появлению науки информатики с более развитой системой понятий, относящихся к изучению информации и информационных процессов. В настоящее время общие положения теоретической кибернетики приобретают в большей степени философское значение. Одновременно активно развиваются прикладные направления кибернетики, связанные с изучением и созданием систем управления в различных предметных областях: техническая кибернетика, медико-биологическая кибернетика, экономическая кибернетика. С развитием компьютерных систем обучения можно говорить о появлении педагогической кибернетики.
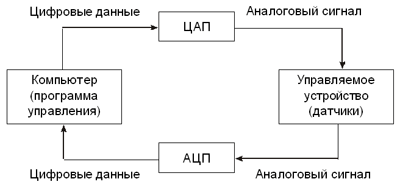
В перечне содержательных линий школьной информатики нет отдельной кибернетической линии. Однако тема кибернетики должна найти отражение в общеобразовательном курсе информатики хотя бы благодаря своей генетической связи с информатикой, описанной выше. Кроме того, применение ИКТ в управлении — одно из важнейших их приложений. Возможны различные пути для включения вопросов кибернетики в общеобразовательный курс. Один путь — через линию алгоритмизации. Алгоритм рассматривается как управляющая информация в кибернетической модели системы управления. В этом контексте раскрывается тема кибернетики. Другой путь — включение темы кибернетики в содержательную линию моделирования. При рассмотрении процесса управления как сложного информационного процесса дается представление о схеме Н.Винера как модели такого процесса. В версии образовательного стандарта для основной школы (2004 г.) эта тема присутствует в контексте моделирования: “кибернетическая модель процессов управления”. В работе А.А. Кузнецова, С.А. Бешенкова и др. “Непрерывный курс информатики” [5] названы три основных направления школьного курса информатики: информационное моделирование, информационные процессы и информационные основы управления. Содержательные линии являются детализацией основных направлений. Таким образом, кибернетической теме — теме управления, придается еще более весомое значение, чем содержательной линии. Это многоплановая тема, которая позволяет затронуть следующие вопросы: — элементы теоретической кибернетики: кибернетическая модель управления с обратной связью; — элементы прикладной кибернетики: структура компьютерных систем автоматического управления (систем с программным управлением); назначение автоматизированных систем управления; — основы теории алгоритмов. Элементы теоретической кибернетики Рассказывая о кибернетической модели управления, учитель должен проиллюстрировать ее примерами, знакомыми и понятными ученикам. При этом должны быть выделены основные элементы кибернетической системы управления: управляющий объект, управляемый объект, каналы прямой и обратной связи. Следует начать с очевидных примеров. Например, шофер и автомобиль. Шофер — управляющий, автомобиль — управляемый объект. Канал прямой связи — система управления автомобилем: педали, руль, рычаги, клавиши и пр. Каналы обратной связи: приборы на панели управления, вид из окон, слух шофера. Всякое воздействие на средства управления можно рассматривать как передаваемую информацию: “увеличить скорость”, “затормозить”, “повернуть направо” и т.д. Информация, передаваемая по каналам обратной связи, также является необходимой для успешного управления. Предложите ученикам задание: что произойдет, если отключить один из каналов прямой или обратной связи? Обсуждение таких ситуаций обычно бывает очень оживленным. Управление с обратной связью называют адаптивным управлением. Действия управляющего адаптируются (т.е. подстраиваются) к состоянию объекта управления, окружающей среды. Самый близкий ученикам пример управления в социальной системе: учитель, управляющий процессом обучения на уроке. Обсудите различные формы управляющего воздействия учителя на учеников: речь, жесты, мимика, записи на доске. Предложите ученикам перечислить различные формы обратной связи; объяснить, как адаптирует учитель ход урока по результатам обратной связи, привести примеры такой адаптации. Например, ученики не справились с предложенным заданием, — учитель вынужден повторить объяснение. При изучении данной темы в старших классах можно рассматривать пути управления в крупных социальных системах: управление предприятием со стороны администрации, управление страной государственными органами и т.п. Здесь полезно использовать материал из курса обществознания. Анализируя механизмы прямой и обратной связи в таких системах, обратите внимание учеников на тот факт, что в большинстве случаев существует множество каналов прямой и обратной связи. Они дублируются для того, чтобы повысить надежность работы системы управления. Алгоритмы и управление Эта тема позволяет раскрыть понятие алгоритма с кибернетической точки зрения. Логика раскрытия следующая. Управление — это целенаправленный процесс. Он должен обеспечить определенное поведение объекта управления, достижение определенной цели. А для этого должен существовать план управления. Этот план реализуется через последовательность управляющих команд, передаваемых по прямой связи. Такая последовательность команд называется алгоритмом управления. Алгоритм управления является информационной компонентой системы управления. Например, учитель ведет урок согласно заранее составленному плану. Шофер ведет автомобиль по заранее продуманному маршруту. В системах управления, где роль управляющего выполняет человек, алгоритм управления может изменяться, уточняться в процессе работы. Шофер не может спланировать заранее каждое свое действие во время движения; учитель корректирует план урока по его ходу. Если же процессом управляет автоматическое устройство, то детальный алгоритм управления должен быть в него заложен заранее в некотором формализованном виде. В таком случае его называют программой управления. Для хранения программы автоматическое устройство управления должно обладать программной памятью. В данной теме следует раскрыть понятие самоуправляемой системы. Это некоторый единый объект, организм, в котором присутствуют все отмеченные выше компоненты систем управления: управляющие и управляемые части (органы), прямая и обратная информационная связь, управляющая информация — алгоритмы, программы и память для ее хранения. Такими системами являются живые организмы. Наиболее совершенный из них — человек. Человек управляет сам собой. Основным управляющим органом является мозг человека, управляемыми — все части организма. Есть управление осознанное (я делаю, что хочу) и есть подсознательное (управление физиологическими процессами). Подобные процессы происходят и у животных. Однако доля осознанного управления у животных меньше, чем у человека в силу более высокого уровня интеллектуального развития человека. Создание искусственных самоуправляемых систем — одна из сложнейших задач науки и техники. Робототехника — пример такого научно-технического направления. В нем объединяются многие области науки: кибернетика, искусственный интеллект, медицина, математическое моделирование и пр. Элементы прикладной кибернетики Данная тема может быть раскрыта либо в углубленном варианте изучения базового курса информатики, либо — на профильном уровне в старших классах. К задачам технической кибернетики относится разработка и создание технических систем управления на производственных предприятиях, в исследовательских лабораториях, на транспорте и пр. Такие системы называются системами с автоматическим управлением — САУ. В качестве управляющего устройства в САУ используются компьютеры или специализированные контроллеры. Кибернетическая модель управления применительно к САУ представлена на рисунке.
Схема системы автоматического управления Это замкнутая техническая система, которая работает без участия человека. Человек (программист) подготовил программу управления, занес ее в память компьютера. Дальше система работает автоматически. Рассматривая этот вопрос, следует обратить внимание учеников на то, что с преобразованием информации из аналоговой формы в цифровую и обратно (ЦАП — АЦП-преобразование) они уже встречались в других темах или еще встретятся. По такому же принципу работает модем в компьютерных сетях, звуковая карта при вводе-выводе звука (см. “Представление звука” 2). В данной системе аналоговый электрический сигнал, идущий по каналу обратной связи от датчиков управляемого устройства с помощью аналого-цифрового преобразователя (АЦП), превращается в дискретные цифровые данные, поступающие в компьютер. На линии прямой связи работает ЦАП — цифро-аналоговый преобразователь, который выполняет обратное преобразование — цифровых данных, идущих от компьютера в аналоговый электрический сигнал, подаваемый на входные узлы управляемого устройства. Другое направление прикладной кибернетики: автоматизированные системы управления (АСУ). АСУ — это человеко-машинная система. Как правило, АСУ ориентированы на управление деятельностью производственных коллективов, предприятий. Это системы компьютерного сбора, хранения, обработки разнообразной информации, необходимой для работы предприятия. Например, данные о финансовых потоках, наличии сырья, объемах готовой продукции, кадровая информация и т.д. и т.п. Основная цель таких систем — быстро и точно предоставлять руководителям предприятия необходимую информацию для принятия управляющих решений. Задачи, решаемые средствами АСУ, относятся к области экономической кибернетики. Как правило, технической базой таких систем являются локальные компьютерные сети. В АСУ используются разнообразные информационные технологии: базы данных, машинная графика, компьютерное моделирование, экспертные системы и пр. 6. Кодирование информацииКод — система условных знаков (символов) для передачи, обработки и хранения информации (сообщения). Кодирование — процесс представления информации (сообщения) в виде кода. Все множество символов, используемых для кодирования, называется алфавитом кодирования. Например, в памяти компьютера любая информация кодируется с помощью двоичного алфавита, содержащего всего два символа: 0 и 1. Научные основы кодирования были описаны К.Шенноном, который исследовал процессы передачи информации по техническим каналам связи (теория связи, теория кодирования). При таком подходе кодирование понимается в более узком смысле: как переход от представления информации в одной символьной системе к представлению в другой символьной системе. Например, преобразование письменного русского текста в код азбуки Морзе для передачи его по телеграфной связи или радиосвязи. Такое кодирование связано с потребностью приспособить код к используемым техническим средствам работы с информацией (см. “Передача информации” 2). Декодирование — процесс обратного преобразования кода к форме исходной символьной системы, т.е. получение исходного сообщения. Например: перевод с азбуки Морзе в письменный текст на русском языке. В более широком смысле декодирование — это процесс восстановления содержания закодированного сообщения. При таком подходе процесс записи текста с помощью русского алфавита можно рассматривать в качестве кодирования, а его чтение — это декодирование. Цели кодирования и способы кодированияСпособ кодирования одного и того же сообщения может быть разным. Например, русский текст мы привыкли записывать с помощью русского алфавита. Но то же самое можно сделать, используя английский алфавит. Иногда так приходится поступать, посылая SMS по мобильному телефону, на котором нет русских букв, или отправляя электронное письмо на русском языке из-за границы, если на компьютере нет русифицированного программного обеспечения. Например, фразу: “Здравствуй, дорогой Саша!” приходится писать так: “Zdravstvui, dorogoi Sasha!”. Существуют и другие способы кодирования речи. Например, стенография — быстрый способ записи устной речи. Ею владеют лишь немногие специально обученные люди — стенографисты. Стенографист успевает записывать текст синхронно с речью говорящего человека. В стенограмме один значок обозначал целое слово или словосочетание. Расшифровать (декодировать) стенограмму может только стенографист. Приведенные примеры иллюстрируют следующее важное правило: для кодирования одной и той же информации могут быть использованы разные способы; их выбор зависит от ряда обстоятельств: цели кодирования, условий, имеющихся средств. Если надо записать текст в темпе речи — используем стенографию; если надо передать текст за границу — используем английский алфавит; если надо представить текст в виде, понятном для грамотного русского человека, — записываем его по правилам грамматики русского языка. Еще одно важное обстоятельство: выбор способа кодирования информации может быть связан с предполагаемым способом ее обработки. Покажем это на примере представления чисел — количественной информации. Используя русский алфавит, можно записать число “тридцать пять”. Используя же алфавит арабской десятичной системы счисления, пишем: “35”. Второй способ не только короче первого, но и удобнее для выполнения вычислений. Какая запись удобнее для выполнения расчетов: “тридцать пять умножить на сто двадцать семь” или “35 х 127”? Очевидно — вторая. Однако если важно сохранить число без искажения, то его лучше записать в текстовой форме. Например, в денежных документах часто сумму записывают в текстовой форме: “триста семьдесят пять руб.” вместо “375 руб.”. Во втором случае искажение одной цифры изменит все значение. При использовании текстовой формы даже грамматические ошибки могут не изменить смысла. Например, малограмотный человек написал: “Тристо семдесять пят руб.”. Однако смысл сохранился. В некоторых случаях возникает потребность засекречивания текста сообщения или документа, для того чтобы его не смогли прочитать те, кому не положено. Это называется защитой от несанкционированного доступа. В таком случае секретный текст шифруется. В давние времена шифрование называлось тайнописью. Шифрование представляет собой процесс превращения открытого текста в зашифрованный, а дешифрование — процесс обратного преобразования, при котором восстанавливается исходный текст. Шифрование — это тоже кодирование, но с засекреченным методом, известным только источнику и адресату. Методами шифрования занимается наука под названием криптография (см. “Криптография” 2). История технических способов кодирования информацииС появлением технических средств хранения и передачи информации возникли новые идеи и приемы кодирования. Первым техническим средством передачи информации на расстояние стал телеграф, изобретенный в 1837 году американцем Сэмюэлем Морзе. Телеграфное сообщение — это последовательность электрических сигналов, передаваемая от одного телеграфного аппарата по проводам к другому телеграфному аппарату. Эти технические обстоятельства привели С.Морзе к идее использования всего двух видов сигналов — короткого и длинного — для кодирования сообщения, передаваемого по линиям телеграфной связи.
Сэмюэль Финли Бриз Морзе (1791–1872), США Такой способ кодирования получил название азбуки Морзе. В ней каждая буква алфавита кодируется последовательностью коротких сигналов (точек) и длинных сигналов (тире). Буквы отделяются друг от друга паузами — отсутствием сигналов. Самым знаменитым телеграфным сообщением является сигнал бедствия “SOS” (Save Our Souls — спасите наши души). Вот как он выглядит в коде азбуки Морзе, применяемом к английскому алфавиту: ••• ––– ••• Три точки (буква S), три тире (буква О), три точки (буква S). Две паузы отделяют буквы друг от друга. На рисунке показана азбука Морзе применительно к русскому алфавиту. Специальных знаков препинания не было. Их записывали словами: “тчк” — точка, “зпт” — запятая и т.п. Характерной особенностью азбуки Морзе является переменная длина кода разных букв, поэтому код Морзе называют неравномерным кодом. Буквы, которые встречаются в тексте чаще, имеют более короткий код, чем редкие буквы. Например, код буквы “Е” — одна точка, а код твердого знака состоит из шести знаков. Это сделано для того, чтобы сократить длину всего сообщения. Но из-за переменной длины кода букв возникает проблема отделения букв друг от друга в тексте. Поэтому приходится для разделения использовать паузу (пропуск). Следовательно, телеграфный алфавит Морзе является троичным, т.к. в нем используется три знака: точка, тире, пропуск.
Равномерный телеграфный код был изобретен французом Жаном Морисом Бодо в конце XIX века. В нем использовалось всего два разных вида сигналов. Не важно, как их назвать: точка и тире, плюс и минус, ноль и единица. Это два отличающихся друг от друга электрических сигнала. Длина кода всех символов одинаковая и равна пяти. В таком случае не возникает проблемы отделения букв друг от друга: каждая пятерка сигналов — это знак текста. Поэтому пропуск не нужен.
Жан Морис Эмиль Бодо (1845–1903), Франция Код Бодо — это первый в истории техники способ двоичного кодирования информации. Благодаря этой идее удалось создать буквопечатающий телеграфный аппарат, имеющий вид пишущей машинки. Нажатие на клавишу с определенной буквой вырабатывает соответствующий пятиимпульсный сигнал, который передается по линии связи. Принимающий аппарат под воздействием этого сигнала печатает ту же букву на бумажной ленте. В современных компьютерах для кодирования текстов также применяется равномерный двоичный код (см. “Системы кодирования текста” 2).
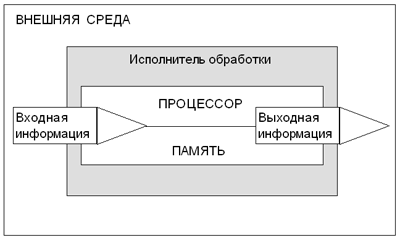
Тема кодирования информации может быть представлена в учебной программе на всех этапах изучения информатики в школе. В пропедевтическом курсе ученикам чаще предлагаются задачи, не связанные с компьютерным кодированием данных и носящие, в некотором смысле, игровую форму. Например, на основании кодовой таблицы азбуки Морзе можно предлагать как задачи кодирования (закодировать русский текст с помощью азбуки Морзе), так и декодирования (расшифровать текст, закодированный с помощью азбуки Морзе). Выполнение таких заданий можно интерпретировать как работу шифровальщика, предлагая различные несложные ключи шифрования. Например, буквенно-цифровой, заменяя каждую букву ее порядковым номером в алфавите. Кроме того, для полноценного кодирования текста в алфавит следует внести знаки препинания и другие символы. Предложите ученикам придумать способ для отличия строчных букв от прописных. При выполнении таких заданий следует обратить внимание учеников на то, что необходим разделительный символ — пробел, поскольку код оказывается неравномерным: какие-то буквы шифруются одной цифрой, какие-то — двумя. Предложите ученикам подумать о том, как можно обойтись без разделения букв в коде. Эти размышления должны привести к идее равномерного кода, в котором каждый символ кодируется двумя десятичными цифрами: А — 01, Б — 02 и т.д. Подборки задач на кодирование и шифрование информации имеются в ряде учебных пособий для школы [4]. В базовом курсе информатики для основной школы тема кодирования в большей степени связывается с темой представления в компьютере различных типов данных: чисел, текстов, изображения, звука (см. “Информационные технологии” 2). В старших классах в содержании общеобразовательного или элективного курса могут быть подробнее затронуты вопросы, связанные с теорией кодирования, разработанной К.Шенноном в рамках теории информации. Здесь существует целый ряд интересных задач, понимание которых требует повышенного уровня математической и программистской подготовки учащихся. Это проблемы экономного кодирования, универсального алгоритма кодирования, кодирования с исправлением ошибок. Подробно многие из этих вопросов раскрываются в учебном пособии “Математические основы информатики” [1]. 7. Обработка информацииОбработка информации — процесс планомерного изменения содержания или формы представления информации. Обработка информации производится в соответствии с определенными правилами некоторым субъектом или объектом (например, человеком или автоматическим устройством). Будем его называть исполнителем обработки информации. Исполнитель обработки, взаимодействуя с внешней средой, получает из нее входную информацию, которая подвергается обработке. Результатом обработки является выходная информация, передаваемая внешней среде. Таким образом, внешняя среда выступает в качестве источника входной информации и потребителя выходной информации. Обработка информации происходит по определенным правилам, известным исполнителю. Правила обработки, представляющие собой описание последовательности отдельных шагов обработки, называются алгоритмом обработки информации. Исполнитель обработки должен иметь в своем составе обрабатывающий блок, который назовем процессором, и блок памяти, в котором сохраняются как обрабатываемая информация, так и правила обработки (алгоритм). Все сказанное схематически представлено на рисунке.
Схема обработки информации Пример. Ученик, решая задачу на уроке, осуществляет обработку информации. Внешней средой для него является обстановка урока. Входной информацией — условие задачи, которое сообщает учитель, ведущий урок. Ученик запоминает условие задачи. Для облегчения запоминания он может использовать записи в тетрадь — внешнюю память. Из объяснения учителя он узнал (запомнил) способ решения задачи. Процессор — это мыслительный аппарат ученика, применяя который для решения задачи, он получает ответ — выходную информацию. Схема, представленная на рисунке, — это общая схема обработки информации, не зависящая от того, кто (или что) является исполнителем обработки: живой организм или техническая система. Именно такая схема реализована техническими средствами в компьютере. Поэтому можно сказать, что компьютер является технической моделью “живой” системы обработки информации. В его состав входят все основные компоненты системы обработки: процессор, память, устройства ввода, устройства вывода (см. “Устройство компьютера” 2). Входная информация, представленная в символьной форме (знаки, буквы, цифры, сигналы), называется входными данными. В результате обработки исполнителем получаются выходные данные. Входные и выходные данные могут представлять собой множество величин — отдельных элементов данных. Если обработка заключается в математических вычислениях, то входные и выходные данные — это множества чисел. На следующем рисунке X: {x1, x2, …, xn} обозначает множество входных данных, а Y: {y1, y2, …, ym} — множество выходных данных:
Схема обработки данных Обработка заключается в преобразовании множества X в множество Y: P(X) Здесь Р обозначает правила обработки, которыми пользуется исполнитель. Если исполнителем обработки информации является человек, то правила обработки, по которым он действует, не всегда формальны и однозначны. Человек часто действует творчески, не формально. Даже одинаковые математические задачи он может решать разными способами. Работа журналиста, ученого, переводчика и других специалистов — это творческая работа с информацией, которая выполняется ими не по формальным правилам. Для обозначения формализованных правил, определяющих последовательность шагов обработки информации, в информатике используется понятие алгоритма (см. “Алгоритм” 2). С понятием алгоритма в математике ассоциируется известный способ вычисления наибольшего общего делителя (НОД) двух натуральных чисел, который называют алгоритм Евклида. В словесной форме его можно описать так: 1. Если два числа равны между собой, то за НОД принять их общее значение, иначе перейти к выполнению пункта 2. 2. Если числа разные, то большее из них заменить на разность большего и меньшего из чисел. Вернуться к выполнению пункта 1. Здесь входными данными являются два натуральных числа — х1 и х2. Результат Y — их наибольший общий делитель. Правило (Р) есть алгоритм Евклида: Алгоритм Евклида (х1, х2) Такой формализованный алгоритм легко запрограммировать для современного компьютера. Компьютер является универсальным исполнителем обработки данных. Формализованный алгоритм обработки представляется в виде программы, размещаемой в памяти компьютера. Для компьютера правила обработки (Р) — это программа. Методические рекомендацииОбъясняя тему “Обработка информации”, следует приводить примеры обработки, как связанные с получением новой информации, так и связанные с изменением формы представления информации. Первый тип обработки: обработка, связанная с получением новой информации, нового содержания знаний. К этому типу обработки относится решение математических задач. К этому же типу обработки информации относится решение различных задач путем применения логических рассуждений. Например, следователь по некоторому набору улик находит преступника; человек, анализируя сложившиеся обстоятельства, принимает решение о своих дальнейших действиях; ученый разгадывает тайну древних рукописей и т.п. Второй тип обработки: обработка, связанная с изменением формы, но не изменяющая содержания. К этому типу обработки информации относится, например, перевод текста с одного языка на другой: изменяется форма, но должно сохраниться содержание. Важным видом обработки для информатики является кодирование. Кодирование — это преобразование информации в символьную форму, удобную для ее хранения, передачи, обработки (см. “Кодирование” 2). Структурирование данных также может быть отнесено ко второму типу обработки. Структурирование связано с внесением определенного порядка, определенной организации в хранилище информации. Расположение данных в алфавитном порядке, группировка по некоторым признакам классификации, использование табличного или графового представления — все это примеры структурирования. Особым видом обработки информации является поиск. Задача поиска обычно формулируется так: имеется некоторое хранилище информации — информационный массив (телефонный справочник, словарь, расписание поездов и пр.), требуется найти в нем нужную информацию, удовлетворяющую определенным условиям поиска (телефон данной организации, перевод данного слова на английский язык, время отправления данного поезда). Алгоритм поиска зависит от способа организации информации. Если информация структурирована, то поиск осуществляется быстрее, его можно оптимизировать (см. “Поиск данных” 2). В пропедевтическом курсе информатики популярны задачи “черного ящика”. Исполнитель обработки рассматривается как “черный ящик”, т.е. система, внутренняя организация и механизм работы которой нам не известен. Задача состоит в том, чтобы угадать правило обработки данных (Р), которое реализует исполнитель. Пример 1.
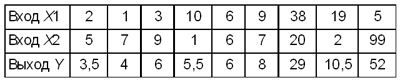
Исполнитель обработки вычисляет среднее значение входных величин: Y = (X1 + X2)/2 Пример 2.
На входе — слово на русском языке, на выходе — число гласных букв. Наиболее глубокое освоение вопросов обработки информации происходит при изучении алгоритмов работы с величинами и программирования (в основной и старшей школе). Исполнителем обработки информации в таком случае является компьютер, а все возможности по обработке заложены в языке программирования. Программирование есть описание правил обработки входных данных с целью получения выходных данных. Следует предлагать ученикам два типа задач: — прямая задача: составить алгоритм (программу) для решения поставленной задачи; — обратная задача: дан алгоритм, требуется определить результат его выполнения путем трассировки алгоритма. При решении обратной задачи ученик ставит себя в положение исполнителя обработки, шаг за шагом выполняя алгоритм. Результаты выполнения на каждом шаге должны отражаться в трассировочной таблице. 8. Передача информацииСоставляющие процеса передачи информацииПередача информации происходит от источника к получателю (приемнику) информации. Источником информации может быть все, что угодно: любой объект или явление живой или неживой природы. Процесс передачи информации протекает в некоторой материальной среде, разделяющей источника и получателя информации, которая называется каналом передачи информации. Информация передается через канал в форме некоторой последовательности сигналов, символов, знаков, которые называются сообщением. Получатель информации — это объект, принимающий сообщение, в результате чего происходят определенные изменения его состояния. Все сказанное выше схематически изображено на рисунке.
Передача информации Человек получает информацию от всего, что его окружает, посредством органов чувств: слуха, зрения, обоняния, осязания, вкуса. Наибольший объем информации человек получает через слух и зрение. На слух воспринимаются звуковые сообщения — акустические сигналы в сплошной среде (чаще всего — в воздухе). Зрение воспринимает световые сигналы, переносящие изображение объектов. Не всякое сообщение информативно для человека. Например, сообщение на непонятном языке хотя и передается человеку, но не содержит для него информации и не может вызвать адекватных изменений его состояния (см. “Информация” ). Информационный канал может иметь либо естественную природу (атмосферный воздух, через который переносятся звуковые волны, солнечный свет, отраженный от наблюдаемых объектов), либо быть искусственно созданным. В последнем случае речь идет о технических средствах связи. Технические системы передачи информацииПервым техническим средством передачи информации на расстояние стал телеграф, изобретенный в 1837 году американцем Сэмюэлем Морзе. В 1876 году американец А.Белл изобретает телефон. На основании открытия немецким физиком Генрихом Герцем электромагнитных волн (1886 г.), А.С. Поповым в России в 1895 году и почти одновременно с ним в 1896 году Г.Маркони в Италии, было изобретено радио. Телевидение и Интернет появились в ХХ веке. Все перечисленные технические способы информационной связи основаны на передаче на расстояние физического (электрического или электромагнитного) сигнала и подчиняются некоторым общим законам. Исследованием этих законов занимается теория связи, возникшая в 1920-х годах. Математический аппарат теории связи — математическую теорию связи, разработал американский ученый Клод Шеннон.
Клод Элвуд Шеннон (1916–2001), США Клодом Шенноном была предложена модель процесса передачи информации по техническим каналам связи, представленная схемой.
Техническая система передачи информации Под кодированием здесь понимается любое преобразование информации, идущей от источника, в форму, пригодную для ее передачи по каналу связи. Декодирование — обратное преобразование сигнальной последовательности. Работу такой схемы можно пояснить на знакомом всем процессе разговора по телефону. Источником информации является говорящий человек. Кодирующим устройством — микрофон телефонной трубки, с помощью которого звуковые волны (речь) преобразуются в электрические сигналы. Каналом связи является телефонная сеть (провода, коммутаторы телефонных узлов, через которые проходит сигнал). Декодирующим устройством является телефонная трубка (наушник) слушающего человека — приемника информации. Здесь пришедший электрический сигнал превращается в звук. Современные компьютерные системы передачи информации — компьютерные сети, работают по тому же принципу. Есть процесс кодирования, преобразующий двоичный компьютерный код в физический сигнал того типа, который передается по каналу связи. Декодирование заключается в обратном преобразовании передаваемого сигнала в компьютерный код. Например, при использовании телефонных линий в компьютерных сетях функции кодирования-декодирования выполняет прибор, который называется модемом. Пропускная способность канала и скорость передачи информацииРазработчикам технических систем передачи информации приходится решать две взаимосвязанные задачи: как обеспечить наибольшую скорость передачи информации и как уменьшить потери информации при передаче. Клод Шеннон был первым ученым, взявшимся за решение этих задач и создавшим новую для того времени науку — теорию информации. К.Шеннон определил способ измерения количества информации, передаваемой по каналам связи. Им было введено понятие пропускной способности канала, как максимально возможной скорости передачи информации. Эта скорость измеряется в битах в секунду (а также килобитах в секунду, мегабитах в секунду). Пропускная способность канала связи зависит от его технической реализации. Например, в компьютерных сетях используются следующие средства связи: — телефонные линии, — электрическая кабельная связь, — оптоволоконная кабельная связь, — радиосвязь. Пропускная способность телефонных линий — десятки, сотни Кбит/с; пропускная способность оптоволоконных линий и линий радиосвязи измеряется десятками и сотнями Мбит/с. Шум, защита от шума Термином “шум” называют разного рода помехи, искажающие передаваемый сигнал и приводящие к потере информации. Такие помехи прежде всего возникают по техническим причинам: плохое качество линий связи, незащищенность друг от друга различных потоков информации, передаваемых по одним и тем же каналам. Иногда, беседуя по телефону, мы слышим шум, треск, мешающие понять собеседника, или на наш разговор накладывается разговор совсем других людей. Наличие шума приводит к потере передаваемой информации. В таких случаях необходима защита от шума. В первую очередь применяются технические способы защиты каналов связи от воздействия шумов. Например, использование экранированного кабеля вместо “голого” провода; применение разного рода фильтров, отделяющих полезный сигнал от шума, и пр. Клодом Шенноном была разработана теория кодирования, дающая методы борьбы с шумом. Одна из важных идей этой теории состоит в том, что передаваемый по линии связи код должен быть избыточным. За счет этого потеря какой-то части информации при передаче может быть компенсирована. Например, если при разговоре по телефону вас плохо слышно, то, повторяя каждое слово дважды, вы имеете больше шансов на то, что собеседник поймет вас правильно. Однако нельзя делать избыточность слишком большой. Это приведет к задержкам и удорожанию связи. Теория кодирования позволяет получить такой код, который будет оптимальным. При этом избыточность передаваемой информации будет минимально возможной, а достоверность принятой информации — максимальной. В современных системах цифровой связи для борьбы с потерей информации при передаче часто применяется следующий прием. Все сообщение разбивается на порции — пакеты. Для каждого пакета вычисляется контрольная сумма (сумма двоичных цифр), которая передается вместе с данным пакетом. В месте приема заново вычисляется контрольная сумма принятого пакета и, если она не совпадает с первоначальной суммой, передача данного пакета повторяется. Так будет происходить до тех пор, пока исходная и конечная контрольные суммы не совпадут. Методические рекомендацииРассматривая передачу информации в пропедевтическом и базовом курсах информатики, прежде всего следует обсудить эту тему с позиции человека как получателя информации. Способность к получению информации из окружающего мира — важнейшее условие существования человека. Органы чувств человека — это информационные каналы человеческого организма, осуществляющее связь человека с внешней средой. По этому признаку информацию делят на зрительную, звуковую, обонятельную, тактильную, вкусовую. Обоснование того факта, что вкус, обоняние и осязание несут человеку информацию, заключается в следующем: мы помним запахи знакомых объектов, вкус знакомой пищи, на ощупь узнаем знакомые предметы. А содержимое нашей памяти — это сохраненная информация. Следует рассказать ученикам, что в мире животных информационная роль органов чувств отличается от человеческой. Важную информационную функцию для животных выполняет обоняние. Обостренное обоняние служебных собак используется правоохранительными органами для поиска преступников, обнаружения наркотиков и пр. Зрительное и звуковое восприятие животных отличается от человеческого. Например, известно, что летучие мыши слышат ультразвук, а кошки видят в темноте (с точки зрения человека). В рамках данной темы ученики должны уметь приводить конкретные примеры процесса передачи информации, определять для этих примеров источник, приемник информации, используемые каналы передачи информации. При изучении информатики в старших классах следует познакомить учеников с основными положениями технической теории связи: понятия кодирование, декодирование, скорость передачи информации, пропускная способность канала, шум, защита от шума. Эти вопросы могут быть рассмотрены в рамках темы “Технические средства компьютерных сетей”. 9. Представление чиселЧисла в математикеЧисло — важнейшее понятие математики, которое складывалось и развивалось в течение длительного периода истории человечества. Люди начали работать с числами еще с первобытных времен. Первоначально человек оперировал лишь целыми положительными числами, которые называются натуральными числами: 1, 2, 3, 4, … Долго существовало мнение о том, что есть самое большое число, “боле сего несть человеческому уму разумевати” (так писали в старославянских математических трактатах). Развитие математической науки привело к выводу, что самого большого числа нет. С математической точки зрения ряд натуральных чисел бесконечен, т.е. неограничен. С появлением в математике понятия отрицательного числа (Р.Декарт, XVII век в Европе; в Индии значительно раньше) оказалось, что множество целых чисел неограниченно как “слева”, так и “справа”. Математическое множество целых чисел дискретно и неограниченно (бесконечно). Понятие вещественного (или действительного) числа в математику ввел Исаак Ньютон в XVIII веке. С математической точки зрения множество вещественных чисел бесконечно и непрерывно. Оно включает в себя множество целых чисел и еще бесконечное множество нецелых чисел. Между двумя любыми точками на числовой оси лежит бесконечное множество вещественных чисел. С понятием вещественного числа связано представление о непрерывной числовой оси, любой точке которой соответствует вещественное число. Далее будет говориться об особенностях представления чисел в вычислительных устройствах: компьютерах, калькуляторах. Представление целых чиселВ памяти компьютера числа хранятся в двоичной системе счисления (см. “Системы счисления” 2). Есть две формы представления целых чисел в компьютере: целые без знака и целые со знаком. Целые без знака — это множество положительных чисел в диапазоне [0, 2k–1] , где k — это разрядность ячейки памяти, выделяемой под число. Например, если под целое число выделяется ячейка памяти размером в 16 разрядов (2 байта), то самое большое число будет таким:
В десятичной системе счисления это соответствует: 216 – 1 = 65 535 Если во всех разрядах ячейки нули, то это будет ноль. Таким образом, в 16-разрядной ячейке помещается 216 = 65 536 целых чисел. Целые числа со знаком — это множество положительных и отрицательных чисел в диапазоне [–2k–1 , 2k–1 – 1]. Например, при k = 16 диапазон представления целых чисел: [–32 768, 32 767]. Старший разряд ячейки памяти хранит знак числа: 0 — число положительное, 1 — число отрицательное. Самое большое положительное число 32 767 имеет следующее представление:
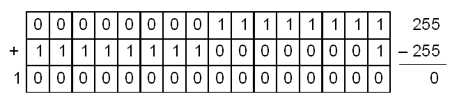
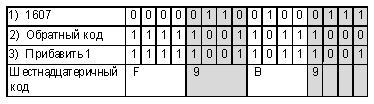
Например, десятичное число 255 после перевода в двоичную систему счисления и вписывания в 16-разрядную ячейку памяти будет иметь следующее внутреннее представление:
Отрицательные целые числа представляются в дополнительном коде. Дополнительный код положительного числа N — это такое его двоичное представление, которое при сложении с кодом числа N дает значение 2k. Здесь k — количество разрядов в ячейке памяти. Например, дополнительный код числа 255 будет следующим:
Это и есть представление отрицательного числа –255. Сложим коды чисел 255 и –255:
Единичка в старшем разряде “выпала” из ячейки, поэтому сумма получилась равной нулю. Но так и должно быть: N + (–N) = 0. Процессор компьютера операцию вычитания выполняет как сложение с дополнительным кодом вычитаемого числа. При этом переполнение ячейки (выход за предельные значения) не вызывает прерывания выполнения программы. Это обстоятельство программист обязан знать и учитывать! Формат представления вещественных чисел в компьютере называется форматом с плавающей точкой. Вещественное число R представляется в виде произведения мантиссы m на основание системы счисления n в некоторой целой степени p, которую называют порядком: R = m ? np. Представление числа в форме с плавающей точкой неоднозначно. Например, для десятичного числа 25,324 справедливы следующие равенства: 25,324 = 2,5324 ? 101 = 0,0025324 ? 104 = 2532,4 ? 10–2 и т.п. Чтобы не было неоднозначности,
договорились в ЭВМ использовать нормализованное
представление числа в форме с плавающей точкой.
Мантисса в нормализованном представлении
должна удовлетворять условию: 0,1n В памяти компьютера мантисса представляется как целое число, содержащее только значащие цифры (0 целых и запятая не хранятся). Следовательно, внутреннее представление вещественного числа сводится к представлению пары целых чисел: мантиссы и порядка. В разных типах компьютеров применяются различные варианты представления чисел в форме с плавающей точкой. Рассмотрим один из вариантов внутреннего представления вещественного числа в четырехбайтовой ячейке памяти. В ячейке должна содержаться следующая информация о числе: знак числа, порядок и значащие цифры мантиссы.
В старшем бите 1-го байта хранится знак числа: 0 обозначает плюс, 1 — минус. Оставшиеся 7 бит первого байта содержат машинный порядок. В следующих трех байтах хранятся значащие цифры мантиссы (24 разряда). В семи двоичных разрядах помещаются двоичные числа в диапазоне от 0000000 до 1111111. Значит, машинный порядок изменяется в диапазоне от 0 до 127 (в десятичной системе счисления). Всего 128 значений. Порядок, очевидно, может быть как положительным, так и отрицательным. Разумно эти 128 значений разделить поровну между положительными и отрицательными значениями порядка: от –64 до 63. Машинный порядок смещен относительно математического и имеет только положительные значения. Смещение выбирается так, чтобы минимальному математическому значению порядка соответствовал ноль. Связь между машинным порядком (Mp) и математическим (p) в рассматриваемом случае выражается формулой: Mp = p + 64. Полученная формула записана в десятичной системе. В двоичной системе формула имеет вид: Mp2 = p2 + 100 00002. Для записи внутреннего представления вещественного числа необходимо: 1) перевести модуль данного числа в двоичную систему счисления с 24 значащими цифрами, 2) нормализовать двоичное число, 3) найти машинный порядок в двоичной системе счисления, 4) учитывая знак числа, выписать его представление в четырехбайтовом машинном слове.
Пример. Записать внутреннее представление числа 250,1875 в форме с плавающей точкой.
Решение 1. Переведем его в двоичную систему счисления с 24 значащими цифрами: 250,187510 = 11111010,00110000000000002. 2. Запишем в форме нормализованного двоичного числа с плавающей точкой: 0,111110100011000000000000 Ч 1021000. Здесь мантисса, основание системы
счисления 3. Вычислим машинный порядок в двоичной системе счисления: Mp2 = 1000 + 100 0000 = 100 1000. 4. Запишем представление числа в четырехбайтовой ячейке памяти с учетом знака числа
Шестнадцатеричная форма: 48FA3000. Диапазон вещественных чисел значительно шире диапазона целых чисел. Положительные и отрицательные числа расположены симметрично относительно нуля. Следовательно, максимальное и минимальное числа равны между собой по модулю. Наименьшее по абсолютной величине число равно нулю. Наибольшее по абсолютной величине число в форме с плавающей точкой — это число с самой большой мантиссой и самым большим порядком. Для четырехбайтового машинного слова таким числом будет: 0,111111111111111111111111 · 1021111111. После перевода в десятичную систему счисления получим: MAX = (1 – 2–24) · 263 Если при вычислениях с вещественными числами результат выходит за пределы допустимого диапазона, то выполнение программы прерывается. Такое происходит, например, при делении на ноль, или на очень маленькое число, близкое к нулю. Вещественные числа, разрядность мантиссы которых превышает число разрядов, выделенных под мантиссу в ячейке памяти, представляются в компьютере приближенно (с “обрезанной” мантиссой). Например, рациональное десятичное число 0,1 в компьютере будет представлено приближенно (округленно), поскольку в двоичной системе счисления его мантисса имеет бесконечное число цифр. Следствием такой приближенности является погрешность машинных вычислений с вещественными числами. Вычисления с вещественными числами компьютер выполняет приближенно. Погрешность таких вычислений называют погрешностью машинных округлений. Множество вещественных чисел, точно представимых в памяти компьютера в форме с плавающей точкой, является ограниченным и дискретным. Дискретность является следствием ограниченного числа разрядов мантиссы, о чем говорилось выше. Количество вещественных чисел, точно
представимых в памяти компьютера, можно
вычислить по формуле: N = 2t · (U
– L + 1) + 1. Здесь t — количество двоичных
разрядов мантиссы; U — максимальное значение
математического порядка; L — минимальное
значение порядка. Для рассмотренного выше
варианта представления (t = 24, U = 63, Тема представления числовой информации в компьютере присутствует как в стандарте для основной школы, так и для старших классов. В основной школе (базовый курс) достаточно рассмотреть представление целых чисел в компьютере. Изучение этого вопроса возможно только после знакомства с темой “Системы счисления”. Кроме того, из принципов архитектуры ЭВМ ученики должны знать о том, что компьютер работает с двоичной системой счисления. Рассматривая представление целых чисел, основное внимание нужно обращать на ограниченность диапазона целых чисел, на связь этого диапазона с разрядностью выделяемой ячейки памяти — k. Для положительных чисел (без знака): [0, 2k–1], для положительных и отрицательных чисел (со знаком): [–2k–1, 2k–1 – 1]. Получение внутреннего представления чисел следует разбирать на примерах. После чего, по аналогии, ученики должны самостоятельно решать такие задачи. Пример 1. Получить внутреннее представление в формате “со знаком” целого числа 1607 в двухбайтовой ячейке памяти. Решение 1) Перевести число в двоичную систему счисления: 160710 = 110010001112. 2) Дописывая слева нули до 16 разрядов, получим внутреннее представление этого числа в ячейке:
Желательно показать, как для сжатой формы записи этого кода используется шестнадцатеричная форма, которая получается заменой каждой четверки двоичных цифр одной шестнадцатеричной цифрой: 0647 (см. “Системы счисления” 2). Более сложной является задача получения внутреннего представления отрицательного целого числа (–N) — дополнительного кода. Нужно показать ученикам алгоритм этой процедуры: 1) получить внутреннее представление положительного числа N; 2) получить обратный код этого числа заменой 0 на 1 и 1 на 0; 3) к полученному числу прибавить 1. Пример 2. Получить внутреннее представление целого отрицательного числа –1607 в двухбайтовой ячейке памяти. Решение
Полезно показать ученикам, как выглядит внутреннее представление самого маленького отрицательного числа. В двухбайтовой ячейке это –32 768. 1) легко перевести число 32 768 в двоичную систему счисления, поскольку 32 768 = 215. Следовательно, в двоичной системе это: 1000000000000000 2) запишем обратный код: 0111111111111111 3) прибавим единицу к этому двоичному числу, получим
Единичка в первом бите обозначает знак “минус”. Не нужно думать, что полученный код — это минус ноль. Это –32 768 в форме дополнительного кода. Таковы правила машинного представления целых чисел. Показав этот пример, предложите ученикам самостоятельно доказать, что при сложении кодов чисел 32 767 + (–32 768) получится код числа –1. Согласно стандарту, представление вещественных чисел должно изучаться в старших классах. При изучении информатики в 10–11-х классах на базовом уровне достаточно качественно рассказать ученикам об основных особенностях работы компьютера с вещественными числами: об ограниченности диапазона и прерывании работы программы при выходе за него; о погрешности машинных вычислений с вещественными числами, о том, что вычисления с вещественными числами компьютер производит медленнее, чем с целыми числами. Изучение на профильном уровне требует подробного разбора способов представления вещественных чисел в формате с плавающей точкой, анализа особенностей выполнения вычислений на компьютере с вещественными числами. Очень важной проблемой здесь является оценка погрешности вычислений, предупреждение от потери значения, от прерывания работы программы. Подробный материал по этим вопросам имеется в учебном пособии [1]. 10. Система счисленияСистема счисления — это способ изображения чисел и соответствующие ему правила действия над числами. Разнообразные системы счисления, которые существовали раньше и которые используются в наше время, можно разделить на непозиционные и позиционные. Знаки, используемые при записи чисел, называются цифрами. В непозиционных системах счисления значение цифры не зависит от положения в числе. Примером непозиционной системы счисления является римская система (римские цифры). В римской системе в качестве цифр используются латинские буквы:
Пример 1. Число CCXXXII складывается из двух сотен, трех десятков и двух единиц и равно двумстам тридцати двум. В римских числах цифры записываются слева направо в порядке убывания. В таком случае их значения складываются. Если же слева записана меньшая цифра, а справа — большая, то их значения вычитаются. Пример 2. VI = 5 + 1 = 6; IV = 5 – 1 = 4. Пример 3. MCMXCVIII = 1000 + (–100 + 1000) + + (–10 + 100) + 5 + 1 + 1 + 1 = 1998. В позиционных системах счисления величина, обозначаемая цифрой в записи числа, зависит от ее позиции. Количество используемых цифр называется основанием позиционной системы счисления. Система счисления, применяемая в современной математике, является позиционной десятичной системой. Ее основание равно десяти, т.к. запись любых чисел производится с помощью десяти цифр: 0, 1, 2, 3, 4, 5, 6, 7, 8, 9. Позиционный характер этой системы легко понять на примере любого многозначного числа. Например, в числе 333 первая тройка означает три сотни, вторая — три десятка, третья — три единицы. Для записи чисел в позиционной системе с основанием n нужно иметь алфавит из n цифр. Обычно для этого при n < 10 используют n первых арабских цифр, а при n > 10 к десяти арабским цифрам добавляют буквы. Вот примеры алфавитов нескольких систем:
Если требуется указать основание системы, к которой относится число, то оно приписывается нижним индексом к этому числу. Например: 1011012, 36718, 3B8F16. В системе счисления с основанием q (q-ичная система счисления) единицами разрядов служат последовательные степени числа q. q единиц какого-либо разряда образуют единицу следующего разряда. Для записи числа в q-ичной системе счисления требуется q различных знаков (цифр), изображающих числа 0, 1, ..., q – 1. Запись числа q в q-ичной системе счисления имеет вид 10. Развернутая форма записи числа Пусть Aq — число в системе с основанием q, аi — цифры данной системы счисления, присутствующие в записи числа A, n + 1 — число разрядов целой части числа, m — число разрядов дробной части числа:
Развернутой формой числа А называется запись в виде:
Например, для десятичного числа:
В следующих примерах приводится развернутая форма шестнадцатеричного и двоичного чисел:
В любой системе счисления ее основание записывается как 10. Если все слагаемые в развернутой форме недесятичного числа представить в десятичной системе и вычислить полученное выражение по правилам десятичной арифметики, то получится число в десятичной системе, равное данному. По этому принципу производится перевод из недесятичной системы в десятичную. Например, перевод в десятичную систему написанных выше чисел производится так:
Перевод целых чисел Целое десятичное число X требуется
перевести в систему с основанием q: X = (anan-1
…a1a0)q. Нужно найти
значащие цифры числа:
Отсюда видно, что a0 есть остаток от деления числа X на число q. Выражение в скобках — целое частное от этого деления. Обозначим его за X1. Выполняя аналогичные преобразования, получим:
Следовательно, a1 есть остаток от деления X1 на q. Продолжая деление с остатком, будем получать последовательность цифр искомого числа. Цифра an в этой цепочке делений будет последним частным, меньшим q. Сформулируем полученное правило: для того чтобы перевести целое десятичное число в систему счисления с другим основанием, нужно: 1) основание новой системы счисления выразить в десятичной системе счисления и все последующие действия производить по правилам десятичной арифметики; 2) последовательно выполнять деление данного числа и получаемых неполных частных на основание новой системы счисления до тех пор, пока не получим неполное частное, меньшее делителя; 3) полученные остатки, являющиеся цифрами числа в новой системе счисления, привести в соответствие с алфавитом новой системы счисления; 4) составить число в новой системе счисления, записывая его, начиная с последнего частного. Пример 1. Перевести число 3710 в двоичную систему. Для обозначения цифр в записи числа используем символику: a5a4a3a2a1a0
Отсюда: 3710 = l00l0l2 Пример 2. Перевести десятичное число 315 в восьмеричную и в шестнадцатеричную системы:
Отсюда следует: 31510 = 4738 = 13B16. Напомним, что 1110 = B16. Десятичную дробь X < 1 требуется перевести в систему с основанием q: X = (0, a–1a–2 … a–m+1 a–m)q. Нужно найти значащие цифры числа: a–1, a–2, …, a–m. Представим число в развернутой форме и умножим его на q:
Отсюда видно, что a–1 есть целая часть произведения X на число q. Обозначим за X1 дробную часть произведения и умножим ее на q:
Следовательно, a–2 есть целая часть произведения X1 на число q. Продолжая умножения, будем получать последовательность цифр. Теперь сформулируем правило: для того чтобы перевести десятичную дробь в систему счисления с другим основанием, нужно: 1) последовательно умножать данное число и получаемые дробные части произведений на основание новой системы до тех пор, пока дробная часть произведения не станет равной нулю или не будет достигнута требуемая точность представления числа в новой системе счисления; 2) полученные целые части произведений, являющиеся цифрами числа в новой системе счисления, привести в соответствие с алфавитом новой системы счисления; 3) составить дробную часть числа в новой системе счисления, начиная с целой части первого произведения. Пример 3. Перевести десятичную дробь 0,1875 в двоичную, восьмеричную и шестнадцатеричную системы.
Здесь в левом столбце находится целая часть чисел, а в правом — дробная. Отсюда: 0,187510 = 0,00112 = 0,148 = 0,316 Перевод смешанных чисел, содержащих целую и дробную части, осуществляется в два этапа. Целая и дробная части исходного числа переводятся отдельно по соответствующим алгоритмам. В итоговой записи числа в новой системе счисления целая часть отделяется от дробной запятой (точкой). Методические рекомендацииТема “Системы счисления” имеет прямое отношение к математической теории чисел. Однако в школьном курсе математики она, как правило, не изучается. Необходимость изучения этой темы в курсе информатики связана с тем фактом, что числа в памяти компьютера представлены в двоичной системе счисления, а для внешнего представления содержимого памяти, адресов памяти используют шестнадцатеричную или восьмеричную системы. Это одна из традиционных тем курса информатики или программирования. Являясь смежной с математикой, данная тема вносит вклад также и в фундаментальное математическое образование школьников. Для курса информатики основной интерес представляет знакомство с двоичной системой счисления. Применение двоичной системы счисления в ЭВМ может рассматриваться в двух аспектах: 1) двоичная нумерация, 2) двоичная арифметика, т.е. выполнение арифметических вычислений над двоичными числами. Двоичная нумерацияС двоичной нумерацией ученики встречаются в теме “Представление текста в компьютерной памяти”. Рассказывая о таблице кодировки, учитель должен сообщить ученикам, что внутренний двоичный код символа — это его порядковый номер в двоичной системе счисления. Например, номер буквы S в таблице ASCII равен 83. Восьмиразрядный двоичный код буквы S равен значению этого числа в двоичной системе счисления: 01010011. Двоичные вычисленияСогласно принципу Джона фон Неймана, компьютер производит вычисления в двоичной системе счисления. В рамках базового курса достаточно ограничиться рассмотрением вычислений с целыми двоичными числами. Для выполнения вычислений с многозначными числами необходимо знать правила сложения и правила умножения однозначных чисел. Вот эти правила:
Принцип перестановочности сложения и умножения работает во всех системах счисления. Приемы выполнения вычислений с многозначными числами в двоичной системе аналогичны десятичной. Иначе говоря, процедуры сложения, вычитания и умножения “столбиком” и деления “уголком” в двоичной системе производятся так же, как и в десятичной. Рассмотрим правила вычитания и деления двоичных чисел. Операция вычитания является обратной по отношению к сложению. Из приведенной выше таблицы сложения следуют правила вычитания: 0 — 0 = 0; 1 — 0 = 1; 10 — 1 = 1. Вот пример вычитания многозначных чисел:
Полученный результат можно проверить сложением разности с вычитаемым. Должно получиться уменьшаемое число. Деление — операция обратная
умножению.
Деление на 100 смещает запятую на 2 разряда влево и т.д. В базовом курсе можно не рассматривать сложные примеры деления многозначных двоичных чисел. Хотя способные ученики могут справиться и с ними, поняв общие принципы. Представление информации, хранящейся в компьютерной памяти в ее истинном двоичном виде, весьма громоздко из-за большого количества цифр. Имеется в виду запись такой информации на бумаге или вывод ее на экран. Для этих целей принято использовать смешанные двоично-восьмеричную или двоично-шестнадцатеричную системы. Существует простая связь между двоичным и шестнадцатеричным представлением числа. При переводе числа из одной системы в другую одной шестнадцатеричной цифре соответствует четырехразрядный двоичный код. Это соответствие отражено в двоично-шестнадцатеричной таблице: Двоично-шестнадцатеричная таблица
Такая связь основана на том, что 16 = 24 и число различных четырехразрядных комбинаций из цифр 0 и 1 равно 16: от 0000 до 1111. Поэтому перевод чисел из шестнадцатеричных в двоичные и обратно производится путем формальной перекодировки по двоично-шестнадцатеричной таблице. Вот пример перевода 32-разрядного двоичного кода в 16-ричную систему: 1011 1100 0001 0110 1011 1111 0010 1010 Если дано шестнадцатеричное представление внутренней информации, то его легко перевести в двоичный код. Преимущество шестнадцатеричного представления состоит в том, что оно в 4 раза короче двоичного. Желательно, чтобы ученики запомнили двоично-шестнадцатеричную таблицу. Тогда действительно для них шестнадцатеричное представление станет эквивалентным двоичному. В двоично-восьмеричной системе каждой восьмеричной цифре соответствует триада двоичных цифр. Эта система позволяет сократить двоичный код в 3 раза. 11. Хранение информацииЧеловек хранит информацию в собственной памяти, а также в виде записей на различных внешних (по отношению к человеку) носителях: на камне, папирусе, бумаге, магнитных и оптических носителях и пр. Благодаря таким записям информация передается не только в пространстве (от человека к человеку), но и во времени — из поколения в поколение. Разнообразие носителей информацииИнформация может храниться в различных видах: в виде текстов, в виде рисунков, схем, чертежей; в виде фотографий, в виде звукозаписей, в виде кино- или видеозаписей. В каждом случае применяются свои носители. Носитель — это материальная среда, используемая для записи и хранения информации. К основным характеристикам носителей информации относятся: информационный объем или плотность хранения информации, надежность (долговечность) хранения. Бумажные носители Носителем, имеющим наиболее массовое употребление, до сих пор остается бумага. Изобретенная во II веке н.э. в Китае, бумага служит людям уже 19 столетий.
Для сопоставления объемов информации на разных носителях будем пользоваться универсальной единицей — байт, считая, что один символ текста “весит” 1 байт. Книга, содержащая 300 страниц, при размере текста на странице примерно 2000 символов имеет информационный объем 600 000 байт, или 586 Кб. Информационный объем средней школьной библиотеки, фонд которой составляет 5000 томов, приблизительно равен 2861 Мб = 2,8 Гб. Что касается долговечности хранения документов, книг и прочей бумажной продукции, то она очень сильно зависит от качества бумаги, от красителей, используемых при записи текста, от условий хранения. Интересно, что до середины XIX века (с этого времени в качестве бумажного сырья начали использовать древесину) бумага делалась из хлопка и текстильных отходов — тряпья. Чернилами служили натуральные красители. Качество рукописных документов того времени было довольно высоким, и они могли храниться тысячи лет. С переходом на древесную основу, с распространением машинописи и средств копирования, с использованием синтетических красителей срок хранения печатных документов снизился до 200–300 лет.
Магнитные носители В XIX веке была изобретена магнитная запись. Первоначально магнитная запись использовалась только для сохранения звука. Самым первым носителем магнитной записи была стальная проволока диаметром до 1 мм. В начале XX столетия для этих целей использовалась также стальная катаная лента. Качественные характеристики всех этих носителей были весьма низкими. Для производства 14-часовой магнитной записи устных докладов на Международном конгрессе в Копенгагене в 1908 г. потребовалось 2500 км, или около 100 кг проволоки. В 20-х годах прошлого века появляется магнитная лента сначала на бумажной, а позднее — на синтетической (лавсановой) основе, на поверхность которой наносится тонкий слой ферромагнитного порошка. Во второй половине XX века на магнитную ленту научились записывать изображение, появляются видеокамеры, видеомагнитофоны. На ЭВМ первого и второго поколений магнитная лента использовалась как единственный вид сменного носителя для устройств внешней памяти. На одну катушку с магнитной лентой, использовавшейся в лентопротяжных устройствах первых ЭВМ, помещалось приблизительно 500 Кб информации. С начала 1960-х годов в употребление входят компьютерные магнитные диски: алюминиевый или пластмассовый диск, покрытый тонким магнитным порошковым слоем толщиной в несколько микрон. Информация на диске располагается по круговым концентрическим дорожкам. Магнитные диски бывают жесткими и гибкими, бывают сменными и встроенными в дисковод компьютера. Последние традиционно называют винчестерами, а сменные гибкие диски — флоппи-дисками. “Винчестер” компьютера — это пакет магнитных дисков, надетых на общую ось. Информационная емкость современных винчестеров измеряется в гигабайтах — десятки и сотни Гб. Наиболее распространенный тип гибкого диска диаметром 3,5 дюйма вмещает 2 Мб данных. Флоппи-диски в последнее время выходят из употребления. В банковской системе большое распространение получили пластиковые карты. На них тоже используется магнитный принцип записи информации, с которой работают банкоматы, кассовые аппараты, связанные с информационной банковской системой. Оптические носители Применение оптического, или лазерного, способа записи информации начинается в 1980-х годах. Его появление связано с изобретением квантового генератора — лазера, источника очень тонкого (толщина порядка микрона) луча высокой энергии. Луч способен выжигать на поверхности плавкого материала двоичный код данных с очень высокой плотностью. Считывание происходит в результате отражения от такой “перфорированной” поверхности лазерного луча с меньшей энергией (“холодного” луча). Благодаря высокой плотности записи оптические диски имеют гораздо больший информационный объем, чем однодисковые магнитные носители. Информационная емкость оптического диска составляет от 190 до 700 Мб. Оптические диски называются компакт-дисками — CD. Во второй половине 1990-х годов появились цифровые универсальные видеодиски DVD (Digital Versatile Disk) с большой емкостью, измеряемой в гигабайтах (до 17 Гб). Увеличение их емкости по сравнению с CD связано с использованием лазерного луча меньшего диаметра, а также двухслойной и двусторонней записи. Вспомните пример со школьной библиотекой. Весь ее книжный фонд можно разместить на одном DVD. В настоящее время оптические диски (CD — DVD) являются наиболее надежными материальными носителями информации, записанной цифровым способом. Эти типы носителей бывают как однократно записываемыми — пригодными только для чтения, так и перезаписываемыми — пригодными для чтения и записи. Флэш-память В последнее время появилось множество мобильных цифровых устройств: цифровые фото- и видеокамеры, МР3-плееры, карманные компьютеры, мобильные телефоны, устройства для чтения электронных книг, GPS-навигаторы и многое другое. Все эти устройства нуждаются в переносных носителях информации. Но поскольку все мобильные устройства довольно миниатюрные, то и к носителям информации для них предъявляются особые требования. Они должны быть компактными, обладать низким энергопотреблением при работе и быть энергонезависимыми при хранении, иметь большую емкость, высокие скорости записи и чтения, долгий срок службы. Всем этим требованиям удовлетворяют флэш-карты памяти. Информационный объем флэш-карты может составлять несколько гигабайт. В качестве внешнего носителя для компьютера широкое распространение получили флэш-брелоки (“флэшки” — называют их в просторечии), выпуск которых начался в 2001 году. Большой объем информации, компактность, высокая скорость чтения-записи, удобство в использовании — основные достоинства этих устройств. Флэш-брелок подключается к USB-порту компьютера и позволяет скачивать данные со скоростью около 10 Мб в секунду. “Нано-носители” В последние годы активно ведутся работы по созданию еще более компактных носителей информации с использованием так называемых “нанотехнологий”, работающих на уровне атомов и молекул вещества. В результате один компакт-диск, изготовленный по нанотехнологии, сможет заменить тысячи лазерных дисков. По предположениям экспертов приблизительно через 20 лет плотность хранения информации возрастет до такой степени, что на носителе объемом примерно с кубический сантиметр можно будет записать каждую секунду человеческой жизни. Организация информационных хранилищИнформация сохраняется на носителях для того, чтобы ее можно было просматривать, искать нужные сведения, нужные документы, пополнять и изменять, удалять данные, потерявшие актуальность. Иначе говоря, хранимая информация нужна человеку для работы с ней. Удобство работы с такими информационными хранилищами сильно зависит от того, как информация организована. Возможны две ситуации: либо данные никак не организованы (такую ситуацию иногда называют кучей), либо данные структурированы. С увеличением объема информации вариант “кучи” становится все более неприемлемым из-за сложности ее практического использования (поиска, обновления и пр.). Под словами “данные структурированы” понимается наличие какой-то упорядоченности данных в их хранилище: в словаре, расписании, архиве, компьютерной базе данных. В справочниках, словарях, энциклопедиях обычно используется линейный алфавитный принцип организации (структурирования) данных. Крупнейшими хранилищами информации являются библиотеки. Упоминания о первых библиотеках относятся к VII веку до н.э. С изобретением книгопечатания (XV век) библиотеки стали распространяться по всему миру. В библиотечном деле имеется многовековой опыт организации информации. Для организации и поиска книг в библиотеках создаются каталоги: списки книжного фонда. Первый библиотечный каталог был создан в знаменитой Александрийской библиотеке в III веке до н.э. С помощью каталога читатель определяет наличие в библиотеке нужной ему книги, а библиотекарь находит ее в книгохранилище. При использовании бумажной технологии каталог — это организованный набор картонных карточек со сведениями о книгах. Существуют алфавитные и систематические каталоги. В алфавитных каталогах карточки упорядочены в алфавитном порядке фамилий авторов и образуют линейную (одноуровневую) структуру данных. В систематическом каталоге карточки систематизированы по тематике содержания книг и образуют иерархическую структуру данных. Например, все книги делятся на художественные, учебные, научные. Учебная литература делится на школьную и вузовскую. Книги для школы делятся по классам и т.д. В современных библиотеках происходит смена бумажных каталогов на электронные. В таком случае поиск книг осуществляется автоматически информационной системой библиотеки. Данные, хранящиеся на компьютерных носителях (дисках), имеют файловую организацию. Файл подобен книге в библиотеке. Аналогично библиотечному каталогу операционная система создает каталог диска, который хранится на специально отведенных дорожках. Пользователь ищет нужный файл, просматривая каталог, после чего операционная система находит этот файл на диске и предоставляет пользователю. На первых дисковых носителях небольшого объема использовалась одноуровневая структура хранения файлов. С появлением жестких дисков большого объема стали использовать иерархическую структуру организации файлов. Наряду с понятием “файл” появилось понятие папки (см. “Файлы и файловая система” 2). Более гибкой системой организации хранения и поиска данных являются компьютерные базы данных (см. “Базы данных” 2). Надежность хранения информацииПроблема надежности хранения информации связана с двумя видами угроз для хранимой информации: разрушение (потеря) информации и кража или утечка конфиденциальной информации. Бумажные архивы и библиотеки всегда были подвержены опасности физического исчезновения. Огромный ущерб для цивилизации принесло разрушение упомянутой выше Александрийской библиотеки в I веке до н.э., поскольку большая часть книг в ней существовала в единственном экземпляре. Основной способ защиты информации в бумажных документах от потери — их дублирование. Использование электронных носителей делает дублирование более простым и дешевым. Однако переход на новые (цифровые) информационные технологии создал новые проблемы защиты информации. Подробнее об этом см. статью “Защита информации” 2. Методические рекомендацииВ процессе изучения курса информатики ученики приобретают определенные знания и умения, относящиеся к хранению информации. Ученики осваивают работу с традиционными (бумажными) источниками информации. В стандарте для основной школы отмечается, что ученики должны научиться работать с некомпьютерными источниками информации: справочниками, словарями, каталогами библиотек. Для этого их следует ознакомить с принципами организации этих источников и с приемами оптимального поиска в них. Поскольку данные знания и умения имеют большое общеучебное значение, то желательно дать их ученикам как можно раньше. В некоторых программах пропедевтического курса информатики этой теме уделяется большое внимание. Ученики должны овладеть приемами работы со сменными компьютерными носителями информации. Все реже в последнее время используются гибкие магнитные диски, на смену которым пришли емкие и быстрые флэш-носители. Ученики должны уметь определять информационную емкость носителя, объем свободного пространства, сопоставлять с ним объемы сохраняемых файлов. Ученики должны понимать, что для длительного хранения больших объемов данных наиболее подходящим средством являются оптические диски. При наличии пишущего CD-дисковода следует научить их организации записи файлов. Важным моментом обучения является разъяснение опасностей, которым подвергается компьютерная информация со стороны вредоносных программ — компьютерных вирусов. Следует научить детей основным правилам “компьютерной гигиены”: осуществлять антивирусный контроль всех вновь поступающих файлов; регулярно обновлять базы антивирусных программ. 12. ЯзыкиОпределение и классификация языковЯзык — это определенная система символьного представления информации. В словаре по школьной информатике, составленном А.П. Ершовым [6], дано такое определение: “Язык — множество символов и совокупность правил, определяющих способы составления из этих символов осмысленных сообщений”. Поскольку под осмысленным сообщением понимается информация, то данное определение по сути своей совпадает с первым. Языки делятся на две группы: естественные и формальные. Естественные языки — это исторически сложившиеся языки национальной речи. Для большинства современных языков характерно наличие устной и письменной форм речи. Анализ естественных языков в большей степени является предметом филологических наук, в частности, лингвистики. В информатике анализом естественных языков занимаются специалисты в области искусственного интеллекта. Одна из целей разработки проекта ЭВМ пятого поколения — научить компьютер понимать естественные языки. Формальные языки — это искусственно созданные языки для профессионального применения. Они, как правило, носят международный характер и имеют письменную форму. Примерами таких языков являются язык математики, язык химических формул, нотная грамота — язык музыки и др. С любым языком связаны следующие понятия: алфавит — множество используемых символов; синтаксис — правила записи языковых конструкций (текста на языке); семантика — смысловая сторона языковых конструкций; прагматика — практические последствия применения текста на данном языке. Для формальных языков характерна принадлежность к ограниченной предметной области (математика, химия, музыка и пр.). Назначение формального языка — адекватное описание системы понятий и отношений, свойственных для данной предметной области. Поэтому все названные выше компоненты языка (алфавит, синтаксис и др.) ориентированы на специфику предметной области. Язык может развиваться, изменяться, дополняться вместе с развитием своей предметной области. Естественные языки не ограничены в своем применении, в этом смысле их можно назвать универсальными. Однако не всегда бывает удобным использовать только естественный язык в узкопрофессиональных областях. В таких случаях люди прибегают к помощи формальных языков. Известны примеры языков, находящихся в промежуточном состоянии между естественными и формальными. Язык эсперанто был создан искусственно для общения людей разных национальностей. А латынь, на которой в древности говорили жители Римской империи, в наше время стала формальным языком медицины и фармакологии, утратив функцию разговорного языка. Языки информатикиДалее речь пойдет о языках, используемых при работе ЭВМ, в компьютерных информационных технологиях. Информация, циркулирующая в компьютере, делится на два вида: обрабатываемая информация (данные) и информация, управляющая работой компьютера (команды, программы, операторы). Информацию, представленную в форме, пригодной для хранения, передачи и обработки компьютером, принято называть данными. Примеры данных: числа при решении математической задачи; символьные последовательности при обработке текстов; изображение, введенное в компьютер путем сканирования, предназначенное для обработки. Способ представления данных в компьютере называется языком представления данных. Для каждого типа данных различается внешнее и внутреннее представление данных. Внешнее представление ориентировано на человека, определяет вид данных на устройствах вывода: на экране, на распечатке. Внутреннее представление — это представление на носителях информации в компьютере, т.е. в памяти, в линиях передачи информации. Компьютер непосредственно оперирует с информацией во внутреннем представлении, а внешнее представление используется для связи с человеком. В самом общем смысле можно сказать, что языком представления данных ЭВМ является язык двоичных кодов. Однако с точки зрения приведенных выше свойств, которыми должен обладать всякий язык: алфавита, синтаксиса, семантики, прагматики, — нельзя говорить об одном общем языке двоичных кодов. Общим в нем является лишь двоичный алфавит: 0 и 1. Но для различных типов данных различаются правила синтаксиса и семантики языка внутреннего представления. Одна и та же последовательность двоичных цифр для разных типов данных имеет совсем разный смысл. Например, двоичный код “0100000100101011” на языке представления целых чисел обозначает десятичное число 16 683, а на языке представления символьных данных обозначает два символа — “А+”. Таким образом, для разных типов данных используются разные языки внутреннего представления. Все они имеют двоичный алфавит, но различаются интерпретацией символьных последовательностей. Языки внешнего представления данных обычно приближены к привычной для человека форме: числа представляются в десятичной системе, при записи текстов используются алфавиты естественных языков, традиционная математическая символика и пр. В представлении структур данных используется удобная табличная форма (реляционные базы данных). Но и в этом случае всегда существуют определенные правила синтаксиса и семантики языка, применяется ограниченное множество допустимых символов. Внутренним языком представления действий над данными (языком управления работой компьютера) является командный язык процессора ЭВМ. К внешним языкам представления действий над данными относятся языки программирования высокого уровня, входные языки пакетов прикладных программ, командные языки операционных систем, языки манипулирования данными в СУБД и пр. Любой язык программирования высокого уровня включает в себя как средства представления данных — раздел данных, так и средства представления действий над данными — раздел операторов (см. “Языки программирования” 2). То же самое относится и к другим перечисленным выше типам компьютерных языков. Среди формальных языков науки
наиболее близким к информатике является язык
математики. В пропедевтическом и базовом курсах информатики большое образовательное значение имеет разговор о языках применительно к человеку. Знакомый ученикам термин “язык” приобретает новый смысл в их сознании. Вокруг этого термина строится целая система научных понятий. Понятие языка является одним из важнейших системообразующих понятий курса информатики. Изучая каждое новое средство ИКТ, следует обращать внимание учеников на то, что для работы с ним пользователь должен овладеть определенным формализованным языком, что его использование требует строгого соблюдения правил языка: знания алфавита, синтаксиса, семантики и прагматики. Такая строгость связана с тем, что формализованные языки, как правило, не обладают избыточностью. Поэтому любое нарушение правил (использование символа, не входящего в алфавит, неправильное употребление разделительных знаков, например, запятой вместо точки и т.п.) приводит к ошибке. Следует обращать внимание учеников на общность некоторых языковых конструкций, используемых в различных технологиях. Например, правила записи формул в электронных таблицах и арифметических выражений в языках программирования практически одинаковы. Существуют и различия, на которые тоже следует обращать внимание. Например, в языках программирования логические связки (NOT, AND, OR) являются знаками операций, а в электронных таблицах — именами функций. Для упрощения работы пользователя в современном программном обеспечении часто применяются различного рода оболочки, обеспечивающие удобный пользовательский интерфейс. Следует объяснять ученикам, что за этими оболочками, как правило, скрыт определенный формализованный язык. Например, за графической оболочкой операционной системы Windows скрывается командный язык ОС. Другой пример: СУБД MS Access предоставляет пользователю возможность для создания БД использовать конструктор таблиц, а для построения запросов — конструктор запросов. Однако за этими высокоуровневыми средствами “скрывается” SQL — универсальный язык описания данных и манипулирования данными. Перейдя в соответствующий режим, можно показать, как выглядят команды на SQL, сформированные в результате работы с конструктором. Библиография разделу “Теоретическая информация”1. Андреева Е.В., Босова Л.Л., Фалина И.Н. Математические основы информатики. Элективный курс. М.: БИНОМ. Лаборатория Знаний, 2005. 2. Бешенков С.А., Ракитина Е.А. Информатика. Систематический курс. Учебник для 10-го класса. М.: Лаборатория Базовых Знаний, 2001, 57 с. 3. Винер Н. Кибернетика, или Управление и связь в животном и машине. М.: Советское радио, 1968, 201 с. 4. Информатика. Задачник-практикум в 2 т. / Под ред. И.Г. Семакина, Е.К. Хеннера. Т. 1. М.: БИНОМ. Лаборатория Знаний, 2005. 5. Кузнецов А.А., Бешенков С.А., Ракитина Е.А., Матвеева Н.В., Милохина Л.В. Непрерывный курс информатики (концепция, система модулей, типовая программа). Информатика и образование, № 1, 2005. 6. Математический энциклопедический словарь. Раздел: “Словарь школьной информатики”. М.: Советская энциклопедия, 1988. 7. Фридланд А.Я. Информатика: процессы, системы, ресурсы. М.: БИНОМ. Лаборатория Знаний, 2003. |