В мир информатики # 96 (16–31 октября).
Эксперимент
Как процессор обменивается данными с памятью
Е.А. Еремин,
г. Пермь
Способы задания адреса в командах и
соответствующие механизмы доступа к ячейкам
памяти составляют важную часть архитектуры
компьютера — систему адресации.
Н.П. Брусенцов [1]
Существует много других режимов
адресации, с некоторыми из них мы столкнемся
позже, но большая их часть нам не понадобится.
П.Нортон [2]
Данная статья продолжает серию
публикаций по работе с отладчиком Debug [3–5].
Напомним, что в статье [3] речь шла о демонстрации
приемов работы с регистрами процессора. Поэтому
вполне логично, что один из выпусков (а именно
сегодняшний) будет посвящен изучению с помощью
Debug способов записи и чтения данных, находящихся
в памяти компьютера. Лишь очень небольшое
количество данных может быть обработано
внутренними средствами процессора с помощью его
немногочисленных регистров. Большая же часть
сколько-нибудь реальных задач требует
запоминания данных (исходных величин,
промежуточных и окончательных результатов) в
памяти. Поэтому способы обмена информацией с
памятью являются одной из важнейших черт
внутреннего устройства компьютера.
Особо хочется подчеркнуть, что
разобраться с базовыми принципами адресации
памяти полезно не только с позиций понимания
внутреннего устройства компьютера и
взаимодействия его блоков. Данный материал имеет
самую непосредственную связь с принципами
хранения различных структур данных; в частности,
в этом выпуске будет подробно показано, как в
памяти организуются такие часто используемые в
программировании структуры, как одномерные и
двумерные массивы, и как с помощью различных
методов адресации осуществляется доступ к
элементам этих массивов.
Для того чтобы картина адресации в
современных компьютерах была ближе к реальности,
в статье также рассмотрены наиболее важные
принципы доступа к памяти в так называемом
“многозадачном режиме” [6]. К сожалению,
проверить этот материал с помощью каких-либо
экспериментов в Debug не удается, поскольку
операционная система скрывает от прикладного
программиста свои внутренние механизмы
адресации.
Несмотря на обилие литературы по
описываемой теме, увидеть за многочисленными
техническими подробностями наиболее важные
положения не так просто. По мнению автора, именно
внимательная “очистка” от второстепенных
деталей и выделение главного делает данную
публикацию оригинальной, отличает ее от уже
существующих. Все подтверждающие теорию
эксперименты разработаны специально для статьи,
что также усиливает ее “нереферативный”
характер. Автор искренне надеется, что
публикуемые материалы будут полезны широкому
кругу читателей, которые задумываются над тем,
каким образом современный процессор находит в
памяти нужную информацию.
1. Краткие сведения об устройстве
памяти
Каждому, кто изучал хотя бы
минимальный курс информатики, известно, что все
данные и программы их обработки хранятся в
компьютере в дискретном двоичном виде.
Согласно классическим принципам, минимально
возможным объемом информации является 1 бит,
и именно бит служит основой компьютерной памяти,
ее минимальным “конструктивным элементом”. В
старых ЭВМ бит можно было в полном смысле слова
увидеть или потрогать руками (см., например,
фотографию в одном из номеров “Информатики” [7]).
В настоящее время благодаря успехам в технологии
производства миниатюрных электронных схем
сформулированный тезис не имеет столь очевидных
(в прямом смысле этого слова!) доказательств, но
тем не менее своей актуальности не утратил.
Бит — слишком маленькая единица
информации, чтобы быть достаточной для
представления практически полезных данных.
Известно, например, что для сохранения в памяти
одного символа требуется 8 бит, стандартного
целого числа — 16, а вообще разрядность
целочисленных данных в современных процессорах
достигла 32 бит. Следовательно, обеспечивать
доступ к каждому отдельному биту памяти
нецелесообразно. Начиная с третьего поколения в
ЭВМ фактически сложился стандарт организации
памяти, при котором минимальной считываемой
порцией информации является 1 байт1.
Кроме того, для работы с более крупными данными
современные процессоры способны одновременно
считывать несколько (как правило, два или четыре)
байт, начиная с заданного.
Итак, минимальной единицей обмена
информацией с памятью в современных компьютерах
является 1 байт. Каждый байт имеет свой
идентификационный номер, по которому к нему
можно обращаться, — его принято называть адресом.
Адреса соседних байтов отличаются на единицу,
зато для двух 32-разрядных чисел, хранящихся в
памяти “друг за другом”, эта разница по понятным
причинам равняется четырем. Практически при
обращении к памяти задается адрес начального
байта и их требуемое количество (см.
разделы 3 и 2 соответственно).
2. Задание размера данных в команде
В семействе процессоров Intel количество
считываемых или записываемых байт определяется
кодом машинной инструкции2. Учитывая, что
первые представители этого семейства имели
разрядность 16 и лишь начиная с модели 80386 перешли
к 32 разрядам, система задания требуемого
количества байт выглядит немного запутанно. Так,
коды команд обращения к байту или слову
отличаются (вполне естественным образом) одним
битом. Например, байтовая команда MOV AL,1 имеет код
B0 01, а двухбайтовая MOV AX,1 — кодируется B8 01 00 (длина
команды увеличилась из-за размера константы!);
легко убедиться, что коды операций B0 и B8
действительно имеют отличие в единственном бите.
Что касается четырехбайтовой команды MOV EAX,1, то
код ее операции абсолютно такой же, как и у
двухбайтовой команды (только константа 1 еще
“длиннее” — 4 байта). Оказывается [8–9], что две
эти одинаковые по кодам команды процессор
различает по установленному режиму: при
обработке 32-разрядного участка памяти константа
заносится в полный регистр EAX, а 16-разрядного — в
его младшую половину AX. Для изменения “режима по
умолчанию” служит специальный префиксный код
(так называемый префикс переключения
разрядности слова, равный 66h), который для
следующей за ним инструкции изменяет
стандартный режим на противоположный3. В
результате при работе в 16-разрядном сегменте4
код 66 B8 01 00 00 00 реализует именно 32-разрядную
операцию записи единицы в EAX.
Примечание. Не пытайтесь проверить
данное утверждение путем ввода в Debug команды MOV
EAX,1 — к сожалению, отладчик “не понимает”
мнемоник, содержащих расширенные регистры!
(Подробнее об использовании 32-битных операций в
Debug см. пункт 3.2.)
Таким образом, мы видим, что
разрядность команды определяется ее кодом (и,
может быть, некоторыми “внешними” по отношению
к программе факторами). Полученный вывод
позволяет нам в дальнейшем ограничиться
рассмотрением методов адресации для данных
какой-либо фиксированной длины: для остальных
достаточно будет просто написать другой код
операции.
3. Задание адреса данных в команде
В предыдущем разделе было показано,
что для понимания методов адресации достаточно
рассмотреть способы задания начального адреса
при фиксированной длине данных. Поэтому в
дальнейшем мы везде будем полагать, что данные
имеют двухбайтовый размер. Для упрощения
понимания идей адресации в большинстве примеров
ограничимся также одной (самой простой!)
инструкцией переписи данных, которая имеет
мнемоническое обозначение MOV. Подчеркнем, что
принятые допущения нисколько не ограничат
общности наших знаний по описываемому вопросу.
Итак, перейдем к рассмотрению основных
принципов обращения к данным, принятых в
компьютерах семейства IBM PC на базе процессоров
фирмы Intel.
3.1. Адресация простых данных
Под простыми данными принято
понимать такие, которые хранят в себе только одно
значение, например, целое число. Сложные данные,
напротив, включают в себя несколько значений,
причем даже не обязательно одного типа5;
простейшим примером “однородных” сложных
данных является массив, о котором мы будем
говорить позднее. Не следует путать сложные
структуры, состоящие из нескольких более простых
значений, в частности из набора целых чисел, с
простыми данными, занимающими в памяти несколько
байт, например, с отдельно взятым 32-разрядным
целым числом.
Будем пока рассматривать адресацию
простых данных, конкретно — это будут целые
16-разрядные числа.
Простейшие и очень часто используемые
инструкции обработки данных, которые
выполняются в регистрах микропроцессора,
настолько естественны, что легко понимаются на
интуитивном уровне.
В частности, речь идет о случаях, когда в регистр
заносится копия содержимого другого регистра (MOV
AX,BX) или константа (MOV AX,30). Тем не менее с
теоретической точки зрения это уже простейшие
методы адресации данных, которые для процессоров
семейства Intel принято называть регистровой
и непосредственной адресацией
соответственно [8–12]. Полный перечень методов
адресации процессоров Intel приводится в
приложении 1 на с. 42.
Чуть более сложным является случай,
когда данные извлекаются из конкретной ячейки
памяти, например, MOV AX,[30]; такой метод получил
название прямой адресации. Приведенная в
качестве примера команда считывает из памяти два
байта, начиная с адреса 30, и помещает их в
16-разрядный регистр AX. Обязательно обратите
внимание на наличие в записи квадратных скобок,
которые всегда появляются при ссылке на
содержимое памяти.
Подобно тому, как заключение в
квадратные скобки константы приводит нас к
появлению прямой адресации, аналогичный прием
для регистра (например, MOV AX,[BX]) также порождает
новый (и очень важный!) метод адресации — косвенный
регистровый. Его суть заключается в том, что
содержимое регистра рассматривается не как
данные, а как адрес памяти, где эти данные
расположены.
Для понимания сущности косвенной
адресации можно рассмотреть следующую аналогию:
при подготовке к экзамену ученик открывает свой
конспект по требуемой теме, а там вместо текста
для ответа видит запись: “Материал по этому
вопросу прочитать в §25”. Иными словами, вместо
готовой информации дается ссылка на нее.
Или еще одна аналогия из книги [13]:
“косвенная адресация похожа на операцию “для
передачи (кому-то)”, выполняемую почтовой
службой США, когда указанный адрес не является
реальным адресом получателя, а является адресом
друга или родственника”.
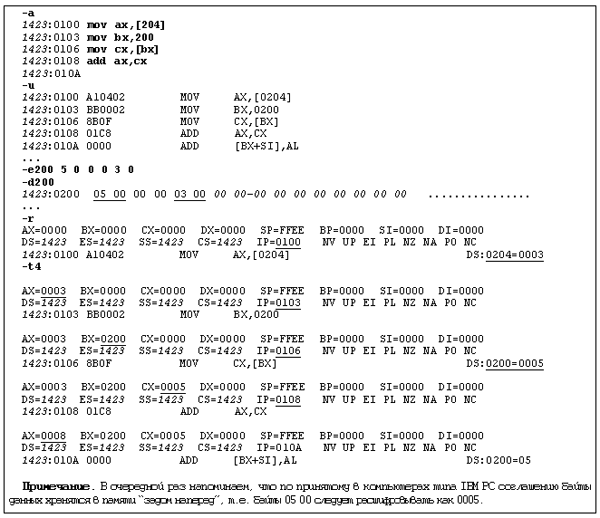
Чтобы закрепить четыре изученных
метода адресации, рассмотрим несложный пример,
который складывает два целых числа, записанные
по адресам 200 и 204. Его выполнение зафиксировано в
протоколе 1 и состоит из нескольких действий:
ввод программы (команда a) и ее вывод для
контроля набора (u); ввод (e200) и
вывод чисел (d200); контроль состояния
регистров до выполнения программы (r);
пошаговое выполнение четырех команд с выводом
значений регистров после каждого шага (t4).
При оформлении протокола приняты те же
правила, что и в предыдущих выпусках. Подчеркнута
информация, на которую при анализе необходимо
обратить особое внимание.
Мы надеемся, читатели без труда
самостоятельно разберут приводимый протокол 1 и
повторят соответствующий диалог в Debug. Не
забудьте только о цели эксперимента —
поработать с четырьмя различными способами
адресации. Поэтому при анализе программы
обязательно обратите внимание на то, какие
методы использованы в каждой из команд (см.
протокол 1).
Протокол 1
Задания для самостоятельной работы
1. Попробуйте модифицировать решение,
приведенное в протоколе 1, так, чтобы доступ к
обеим ячейкам 200 и 204 осуществлялся с помощью
косвенной адресации через регистр BX. Используйте
возможность сложения значения содержимого
первого адреса 200 с константой, равной 4.
2. Придумайте и реализуйте в Debug свою
программу, аналогичную приведенной в протоколе 1.
Литература
1. Брусенцов Н.П. Микрокомпьютеры.
М.: Наука, 1985.
2. Нортон П., Соухэ Д. Язык
ассемблера для IBM PC. М.: Изд-во “Компьютер”;
“Финансы и статистика”, 1992.
3. Заславская О.Ю. Работа с
регистрами центрального процессора. /
Информатика № 1/2005.
4. Еремин Е.А. Еще раз о программе
Debug. / Информатика № 23/2006, 1/2007.
5. Еремин Е.А. Отладчик Debug и язык
ассемблер. / Информатика № 5–7/2007.
6. Усенков Д.Ю. Электронный Юлий
Цезарь, или Как компьютер выполняет программы. /
Информатика № 18/2005.
7. Еремин Е.А. Устройство ОЗУ. /
Информатика № 23/2005.
8. Intel Architecture Software Developer’s Manual, Volume 3: System
Programming. Intel Corp., 1999.
9. Гук М. Процессоры Intel: от 8086 до Pentium
II. СПб.: Питер, 1997.
10. Шагурин И.И., Бердышев Е.М. Процессоры
семейства Intel P6. Архитектура, программирование,
интерфейс. М.: Горячая линия – Телеком, 2000.
11. Смит Б.Э., Джонсон М.Т.
Архитектура и программирование микропроцессора
Intel 80386. М.: Конкорд, 1992.
12. Скэнлон Л. Персональные ЭВМ IBM PC и
XT. Программирование на языке ассемблера. М.: Радио
и связь, 1991.
13. Лиин В. PDP-11 и VAX-11. Архитектура и
программирование на языке ассемблера. М.: Радио и
связь, 1989.
Приложение 1
Методя адресации процессоров
семейства INTEL


1 Сказанное ни в коем случае не
следует понимать как невозможность
использования информации из отдельного бита:
ничто не мешает процессору считать байт целиком,
а затем с помощью логических операций выделить и
проанализировать содержимое конкретного бита в
этом байте. (От ред.: О выделении битов из
числа см. статьи “Логические операции над
числами” и “Еще раз о логических операциях с
числами” в “Информатике” соответственно № 43/2004
и № 24/2005.)
2 А также зависит от режима работы с
памятью, о чем см. далее.
3 Хорошей аналогией влияния
префикса служит клавиша “F” в инженерных
калькуляторах, позволяющая c каждой клавишей
“связать” вторую функцию.
4 Отладчик Debug, родившийся в
16-разрядной операционной системе MS-DOS, работает
именно в таком сегменте.
5 Вспомните тип record (запись) в языке
программирования Паскаль.
* Сокращение “д.п.а.” в столбце “Операнд”
означает “данные из памяти по адресу”.
** Масштабирование индекса возможно
только в 32-битном режиме.
*** Стековый механизм адресации будет
рассмотрен отдельно.
Обозначения:
— EA — эффективный адрес;
— Disp — смещение (от английского слова displacement);
— Base — база;
— Index — индекс;
— Scale — масштаб (количество байт в каждом из
данных).
Продолжение — в следующем
выпуске |